

Как работать с программой файн ридер?
Как пользоваться программой ABBYY FineReader?
Расскажите про основные функции программы ABBYY Finereader, как ими пользоваться?

Finereader — это программа для сканирования и распознавания текста с экспортом информации в популярные офисные пакеты. Принцип работы с ним в двух словах можно описать так: берем бумажный лист с напечатанным текстом, сканируем его сканером, получаем некий графический файл растрового формата. Потом не выходя из программы Finereader распознаем текст файла и следующим шагом делаем из скано-копии документ формата Word. Перед этим распознанный текст можно просмотреть и отредактировать. Полученный word-овский документ можно уже дальше дополнять и редактировать.

Программа ABBYY FineReader — это отличный способ без перепечатки документов вручную перевести их в форматы файлов, которые можно редактировать. Если простыми словами, то при помощи ABBYY FineReader можно книгу перевести, к примеру, в Doc-формат, который можно изменять, копировать, редактировать и т. д.
Для этого у ABBYY FineReader есть все необходимые функции, включая сканирование, перевод картинки в текст, выделение фрагментов и т. д.
Более наглядно посмотреть как пользоваться программой ABBYY FineReader можете в этом видео:

Для того чтобы воспользоватся программой ABBYY FineReader которая предназначена для распознавания текста с нередактируемых и графических форматов. необходимо для начала скачать ее и установить на компьютер, а после посмотреть ролик представленный ниже здесь все подробно рассказано о данной программе.

Программа Abbyyfinereader бесспорно является лидером среди подобных программ.
Она обладает очень широкими возможностями по распознаванию текста с нередактируемых и графических форматов.
Программа сможет распознать текст с таких основных форматов как (нередактируемых pdf,цифровые форматы файлов jpeg, jpg, Djvu, gif, png и т.д. ).
Также программа ABBYY FineReader неплохо работает практически со всеми моделями сканеров.
Основными функциями программы являются:
Сканирование документов в форматы: Microsoft Word, Microsoft Excel, Pdf, сканирование и сохранение изображений, PDF или изображение в Microsoft Word, конвертировать фото в Microsoft Word.
Рабочая область программы ABBYY Finereader :
Для добавления новой задачи, необходимо нажать на кнопку «**новое задание **», которая находится в левой верхней части, рабочей области программы.
Откроется окно «новое задание«

В открывшемся окне необходимо выбрать ту задачу которую нужно выполнить.
Допустим у нас есть фотография документа который мы хотим конвертирывать в формат документа Microsoft Word. Для этого в окне новое задание находим активную надпись «Конвертировать фото в Microsoft Word » и нажимаем на эту надпись. Откроется окно проводника программы с предворительным просмотром :
В открывшемся окне выбираем фото текстового файла которое необходимо распознать и конвертировать в нужный вам формат.
Откроется окно со шкалой процесса распознования:
После того как программа обработает фото и попытается распознать текст.
Вы увидите следующее:
Здесь вы сможете выбрать область вашего фото для распознования текста.
После выбора области нажмите кнопку распознать которая находится в верхнем меню программы. Программа приступит к конвертации выбранного фото в текст. После обработки изображения нажмите на стрелку рядом скнопкой сохранить и выберите нужный формат для создания текстового документа:

Мощная и функциональная программа ABBYY FineReader, предназначена для качественного сканирования и точного распознавания (это зависит от разрешения, выставленного при сканировании) различных бумажных носителей информации с печатным текстом (книг, журналов, газет и т.п.), а также изображений цифрового формата.
Программа поддерживает различные языки распознавания, умеет сохранять в: Microsoft Word, PDF, форматы изображений и другие форматы. Так как программа имеет интуитивно-понятный интерфейс, работать с ней удобно.
Итак, первым делом нужно сначала выставить настройки и отсканировать документ, получим изображение, текст которого следует программе распознать. После распознавания можно подкорректировать текст (если есть какие-либо неточности) и сохранить его в желаемый формат.
Как распознать текст с помощью ABBYY FineReader: пошаговая инструкция

В этот раз расскажу как превращать бумажные документы в электронный вид формата PDF, а также, как бумажный документ перекинуть в компьютер с целью изменить текст. Итак начнем.
У меня на руках бумажный документ.
СКАНИРОВАНИЕ в PDF
Задача: перекинуть в компьютер (перевести в электронный вид) этот документ. Притом нужно сделать именно в таком виде чтобы нельзя было его в будущем изменить (грубо говоря надо сделать фото документа). Потом этот электронный документ нужно переслать по почте на электронный адрес. Притом клиент просит именно в формате pdf.
По этапам:
1) пропускаю документ через сканер
2) сохраняю полученный отпечаток в формате pdf на свой компьютер
3) пересылаю полученный файл по почте
В своей работе я использую для решения такой задачи 2 программы:
Foxit Phantom или ABBYY FineReader. Для понятности прикладываю скриншоты:
В Foxit Phantom при включенном сканере необходимо в главном меню выбрать ФАЙЛ-СОЗДАТЬ PDF-СО СКАНЕРА…
Произойдет сканирование и появится предложение сохранить файл. Выбираем место, пишем название файла и сохраняем.

В ABBYY FineReader в панели инструментов есть огромные кнопки. Одна из них называется СКАНИРОВАТЬ в PDF. Её и используем.

Если же надо отсканировать многостраничный документ то, по этапам:
1) Нажимаем кнопку под номером 1 СКАНИРОВАНИЕ

Получаем отсканированный документ

Также сканируем ещё одну страницу (нажимаем ещё раз кнопку под номером 1 СКАНИРОВАНИЕ).
2) Сохраняем в PDF


В итоге получаем готовый многостраничный документ в виде файла в формате PDF.

Теперь данный файл можно отправлять по электронной почте.
РАСПОЗНАВАНИЕ ТЕКСТА
Задача: перевести бумажный документ в электронный вид (в компьютер)
По этапам:
1) Сканирование (кнопка 1 СКАНИРОВАНИЕ)

2) Распознавание (кнопка 2 РАСПОЗНАТЬ ВСЕ)

Распознавание нужно понимать как процесс перевода фотографии (картинки) в текст (буквы, цифры, знаки). Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
3) Сохранение в текстовый редактор (кнопка 4 Сохранить)
Советую выбирать ПЕРЕДАТЬ ВСЕ СТРАНИЦЫ В—MICROSOFT WORD


Хотелось бы указать на важные моменты при процедуре РАСПОЗНАВАНИЯ. Есть нюансы при работе.
Сразу после распознавания советую поглядеть на результат. Особенно на блоки, которые создает программа FineReader.

Это области выделенные в прямоугольные рамки. Рамки эти разного цвета. Если красного цвета-то этот блок распознался как КАРТИНКА. Если черного цвета — то ТЕКСТ. Блоки бывают разного типа. Тип блока можно узнать щелкнув на блоке ПРАВОЙ клавишей мыши и выбрав ИЗМЕНИТЬ ТИП БЛОКА.

Маленькая хитрость: можно выделить произвольную область и пометить любым типом блок. Например выделим ту часть текста, которая плохо распознается, при помощи левой клавиши мыши (нажимает, удерживаем и тянем, рамка меняет размер).



В итоге документ в Word-е будет иметь блок текста и блок картинка. Блок картинка будет иметь абсолютно неизменный вид. Данный способ я использую при сохранении печатей, нестандартных шрифтов, картинок, фотографий.
ЗЫ: Знания и умения работать с PDF, сканировать и распознавать документы очень часто выручают в офисной работе. Знание — экономит Ваше время!
Как работать в ABBYY FineReader 12

Функциональное решение для сканирования документов ABBYY FineReader предоставляет возможность пользователю выбрать, в каком из популярных текстовых форматов сохранить файл. Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.
ABBYY FineReader 12, имеющаяся в наличии в SoftMagazin, обладает множеством полезных функций и значительно упрощает процесс распознавания текста и перевода его в формат PDF.
Как пользоваться программой ABBYY FineReader 12, описано в инструкции к программе, однако у пользователей могут остаться некоторые вопросы по ее настройке и запуску. В данном обзоре будут даны ответы о работе в ABBYY FineReader, как пользоваться этой программой, в частности последними ее версиями.

ABBYY FineReader: как работать
Для эффективной работы со сканируемыми документами нужно знать, для чего нужна ABBYY FineReader, как пользоваться основными функциями программы и правильно запускать ее. Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
Особых различий в версии ABBYY FineReader 11, и как пользоваться 12 выпуском программы не наблюдается. Обе версии отличаются наличием хорошего функционала, поддержкой более 150 языков, в том числе и языков программирования и математических формул. Чтобы начать пользоваться программой, достаточно установить лицензионную версию на домашний или рабочий ПК и запустить ярлык ABBYY FineReader с рабочего стола или из меню Пуск.
Как установить ABBYY FineReader 11
Для установки программы на ПК нужно после приобретения лицензии, запустить из папки с программой или диска файл setup.exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.


Как запустить ABBYY FineReader
 Запустить ярлык с рабочего стола компьютера
Запустить ярлык с рабочего стола компьютера
Выбрать в меню Пуск раздел Программы и запустить ABBYY FineReader
Если вы пользуетесь приложениями Microsoft Office, то достаточно нажать на инструментальной панели значок программы
Выберите в проводнике нужный документ и нажав правой кнопкой мыши, выберите в появившемся меню «Открыть с помощью ABBYY FineReader».
Как настроить ABBYY FineReader 12 Professional
Профессиональная версия ABBYY FineReader приобретается организациями для эффективной работы с программой в корпоративной сети и совместного редактирования файлов. Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
Все автоматические функции могут использоваться в ручном режиме. Для комфортной работы перейдите на панели инструментов в «Сервис» и выберите пункт «Настройки», чтобы отрегулировать параметры. Можно самостоятельно задать настройки вида документа, режима сканирования, распознавания и сохранения файла.


ABBYY FineReader — как переводить
Для качественной конвертации документов в программе предусмотрены встроенные стандартные задачи, используя которые можно перевести документ в нужный формат, затратив минимум усилий. Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.
Распознавание текста в ABBYY FineReader (1/2)
Систему распознавания текста в FineReader можно описать очень просто.
У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы.

Выглядит очень просто, но дьявол, как обычно, кроется в деталях.
Про уровень от документа до строки текста поговорим как-нибудь в следующий раз. Это большая система, в которой есть много своих сложностей. В качестве некоторого введения, пожалуй, можно оставить здесь вот такую иллюстрацию к алгоритму выделения строк.

В этой статье мы начнём рассказ про распознавание текста от уровня строки и ниже.
Небольшое предупреждение: система распознавания FineReader – очень большая и постоянно дорабатывается в течение многих лет. Описывать эту систему целиком со всеми ее нюансами, во-первых, лучше кодом, во-вторых, займет очень-очень много места, в-третьих, почитайте это. Поэтому к написанному далее рекомендуем относиться как к некой очень обобщенной теории, стоящей за практической системой. То есть общие идеи и направления в технологии примерно похожи на правду, но чтобы понять до мелочей, что же там на практике происходит, лучше не читать эту статью, а работать у нас над разработкой этой системы.
Граф линейного деления
Итак, у нас есть черно-белое изображение строки текста. На самом деле изображение, конечно, серое или цветное, а черно-белым становится после бинаризации (про бинаризацию тоже нужно писать отдельную статью, а пока отчасти может помочь вот это).
Так вот, пусть есть черно-белое изображение строки текста. Нужно его поделить на слова, а слова — на символы для распознавания. Базовая идея, как обычно, очевидна – ищем на изображении строки вертикальные белые просветы, а дальше кластеризуем их по ширине: широкие просветы – это пробелы между словами, узкие – между символами.

Идея замечательная, но в реальной жизни ширина пробелов может быть очень неоднозначным показателем, к примеру, для текста с наклоном или неудачного сочетания символов или слипшегося текста.

Решений у проблемы, в общем, два. Решение первое – считать некую «видимую» ширину просветов. Человек может практически любой текст, даже на незнакомом языке, точно поделить на слова, а слова — на символы. Это происходит потому, что мозг фиксирует не вертикальное расстояние между символами, а некий видимый объем пустого пространства между ними. Решение хорошее, мы его, конечно, используем, только работает оно не всегда. К примеру, текст может быть повреждён при сканировании и некоторые нужные просветы могут уменьшиться или, наоборот, сильно увеличиться.
Это приводит нас ко второму решению – графу линейного деления. Идея в следующем – если есть несколько вариантов, где поделить строку на слова, а слова на буквы, то давайте отметим все возможные точки деления, которые мы смогли придумать. Кусок изображения между двумя отмеченными точками будем считать кандидатом буквы (или слова). Вариант графа линейного может быть простым, если текст хороший и нет проблем с определением точек деления или сложным, если изображение было плохое.


Теперь задача. Есть множества вершин графа, нужно найти путь от первой вершины до последней, проходящий через какое-то количество промежуточных вершин (не обязательно все) с наилучшим качеством. Начинаем думать, что это напоминает. Вспоминаем курс оптимального управления из института, понимаем, что это подозрительно похоже на задачи динамического программирования.
Давайте подумаем, что нам нужно, чтобы алгоритм перебора всех вариантов не взорвался.
Для каждой дуги в графе нужно определить её качество. Если мы работаем с графом линейного деления слова на символы, то каждая дуга у нас – это символ. В роли качества дуги мы используем уверенность распознавания символа (как её посчитать — поговорим позднее). А если работаем с ГЛД на уровне строки, то каждая дуга этого ГЛД – вариант распознавания слова, который в свою очередь был получен из символьного графа. То есть нам нужно уметь оценивать общее качество полного пути в графе линейного деления.
Качество полного пути в графе мы будем определять как сумму качества всех дуг МИНУС штраф за весь вариант. Почему именно минус? Это дает нам возможность быстро оценить максимально возможное качество варианта пути по сумме качества дуг этого пути, а это значит, что большинство вариантов мы будем отсекать еще до подсчета общего качества варианта.
Таким образом, для ГЛД мы приходим к стандартному алгоритму динамического программирования – находим точки линейного деления, строим путь от начала до конца по дугам с наибольшим качеством, высчитываем итоговую стоимость построенного варианта. А дальше перебираем пути в ГЛД в порядке уменьшения суммарного качества элементов с постоянным обновлением найденного лучшего варианта, пока не поймем, что все необработанные варианты заведомо хуже, чем текущий лучший вариант.
Гипотезы изображения
Прежде чем мы спустимся на уровень распознавания отдельных слов, у нас есть еще одна тема, которая не обсуждалась, – гипотезы изображения фрагмента.
Идея в следующем – у нас есть изображение текста, с которым мы собираемся работать. Очень хочется все изображения обрабатывать одинаковым образом, но правда в том, что в реальном мире изображения все разные – они могут быть получены из разных источников, они могут быть разного качества, они могут быть по-разному отсканированы.
С одной стороны, кажется, что разнообразие возможных искажений должно быть очень велико, но если начать разбираться, обнаруживается только ограниченный набор возможных искажений. Поэтому мы используем систему гипотез текста.
У нас есть предопределенный набор возможных гипотез проблемного текста. Для каждой гипотезы нужно определить:
- Быстрый способ выяснить, применима ли данная гипотеза к текущему изображению, причем сделать это только на основе характеристик изображения, до распознавания.
- Метод для исправления на изображении проблем конкретной гипотезы.
- Критерий качества правильности выбора гипотезы по итогам распознавания изображения, плюс, возможно, рекомендации для следующих гипотез.


На изображении выше можно увидеть гипотезы для различной бинаризации и контрастности исходного изображения.
В результате обработка гипотез выглядит так:
- По изображению сгенерировать наиболее подходящую гипотезу.
- Исправить искажения от выбранной гипотезы.
- Распознать полученное изображение.
- Оценить качество распознавания.
- Если качество распознавания улучшилось, то оценить, нужно ли применять новые гипотезы к измененному изображению.
- Если качество ухудшилось, то вернуться к исходному изображению и попробовать применить к нему какую-либо другую гипотезу.
На изображениях показано последовательное применение гипотез белого шума и сжатого текста.
Оценка качества слова
Остались нераскрытыми две важных темы: оценка общего качества распознавания слова и распознавание символов. Распознавание символа – тема на несколько разделов, поэтому сначала обсудим оценку качества распознанного слова.
Итак, у нас есть некий вариант распознавания слова. Первое, что приходит на ум, – проверить его по словарю и дать ему штраф, если оно в словаре не нашлось. Идея хорошая, но не все языки есть словари, не все слова в тексте могут быть словарными (имена собственные, к примеру), и, если уж мы углубляемся в сложности, – не всё в тексте вообще может быть словами в стандартном понимании этого термина.
Чуть раньше мы говорили, что любые оценки за слово целиком должны быть отрицательными, чтобы у нас нормально работал перебор по ГЛД. Сейчас нам это начнет активно мешать, поэтому давайте зафиксируем, что у нас есть некая заранее определенная максимальная положительная оценка слова, слову мы даем положительные бонусы, а финальный отрицательный штраф определяем как разность набранных бонусов и максимальной оценки.
Ок, пусть мы распознаём фразу «Вася прилетает рейсом SU106 в 23.55 20/07/2015». Мы, конечно, можем оценивать здесь качество каждого слова по общим правилам, но это будет достаточно странно. Скажем, и SU106 и Вася вполне понятные в данной строке слова, но очевидно, что правила образования у них разные и, по идее, верификация тоже должна быть разной
Отсюда появляется идея моделей. Модель слова – это некое обобщенное описание конкретного типа слов в языке. У нас, конечно, будет модель стандартного слова в языке, но также будут модели чисел, аббревиатур, дат, сокращений, имен собственных, URL и т.д.
Что нам дают модели и как их нормально использовать? Фактически мы обращаем в обратную сторону нашу систему проверки слова – вместо того чтобы для варианта слова долго узнавать, что же это такое, мы даем каждой модели решать, подходит ли ей данный вариант слова и насколько хорошо она его оценивает.

Из самой постановки задачи формируются наши требования к архитектуре модели. Модель должна уметь:
- Быстро сказать, подходит или нет для нее вариант слова. Стандартная проверка включает все проверки разрешенных наборов символов для каждой буквы в слове. Скажем, в словарном слове пунктуация должна быть только в начале или в конце, а в середине слова набор пунктуации сильно ограничен, и сочетание пунктуации сильно ограничено (супер-способность?!), а в модели числа в основном должны быть цифры, кроме разрешенного в данном языке символьного суффикса (10-ое, 10 th ).
- Уметь по своей внутренней логике оценить качество распознаваемого слова. К примеру, слово из словаря должно явно оцениваться выше, чем просто набор символов.
При оценке качества модели не стоит забывать, что наша задача в итоге – сравнивать модели между собой, поэтому их оценки должны быть согласованы. Более-менее нормальный способ этого добиться – это относиться к оценке модели как к оценке вероятности построить слово по данной модели. Скажем, словарных слов в обычном языке достаточно много, и получить словарное слово при неправильном распознавании несложно. А вот собрать нормальный, подходящий под все правила телефонный номер уже гораздо сложнее.
В итоге при распознавании некоторого фрагмента строки у нас получается примерно такая схема:
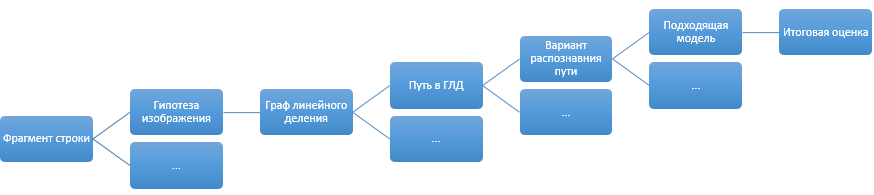
Отдельным пунктом при оценке вариантов распознавания идут дополнительные эмпирические штрафы, не вписывающиеся ни в концепцию моделей, ни в оценку распознавания. Скажем, «ООО Рога и копыта» и «000 Рога и копыта» выглядят как два одинаково нормальных варианта (особенно если в шрифте 0 (ноль) и О (буква О) слабо отличаются пропорциями). Но при этом достаточно очевидно, какой вариант распознавания должен быть правильным. Для таких небольших конкретных знаний о мире сделана отдельная система правил, которая может дополнительно штрафовать не понравившиеся ей варианты после оценок моделей.
Про само распознавание поговорим уже в следующей части этого поста. Подписывайтесь на блог компании, чтобы не пропустить 
мЙЮОЩЕ ЪБРЙУЙ
Linux, РТПЗТБННЩ — РТПВМЕНЩ Й ТЕЫЕОЙС
тБВПФБ Ч РТПЗТБННЕ ABBYY FineReader
ABBYY FineReader 8.0 Professional Edition
тБУУНБФТЙЧБА 8 ЧЕТУЙА РТПЗТБННЩ, ФБЛ ЛБЛ УБНБ ЕА РПМШЪХАУШ.
тБУРПЪОБЧБОЙЕ
оБЦНЙФЕ ЛОПРЛХ уЛБОЙТПЧБФШ (ЙМЙ пФЛТЩФШ, Ч ЪБЧЙУЙНПУФЙ ПФ ЙУФПЮОЙЛБ), ЮФПВЩ ОБЮБФШ УЛБОЙТПЧБОЙЕ. пФЛТПЕФУС ПЛОП РТПЗТБННЩ УЛБОЙТПЧБОЙС. ч ВПМШЫЙОУФЧЕ УМХЮБЕЧ ПРФЙНБМШОЩН ТБЪТЕЫЕОЙЕН ВХДЕФ 300dpi, ТЕЦЙН УЛБОЙТПЧБОЙС РТЙ ЬФПН МХЮЫЕ ХУФБОБЧМЙЧБФШ, ПТЙЕОФЙТХСУШ ОБ ФП, ЛБЛЙЕ ЬМЕНЕОФЩ РТЙУХФУФЧХАФ Ч ДПЛХНЕОФЕ (ФПМШЛП ФЕЛУФ, ФЕЛУФ У ЗТБЖЙЛБНЙ ЙМЙ ДЙБЗТБННБНЙ, ФЕЛУФ У ЙММАУФТБГЙСНЙ).
дМС ФПЗП, ЮФПВЩ ПФУЛБОЙТПЧБФШ ОЕУЛПМШЛП УФТБОЙГ РПДТСД, ОБЦНЙФЕ ОБ УФТЕМЛХ УРТБЧБ ПФ ЛОПРЛЙ уЛБОЙТПЧБФШ, ЧЩВЕТЙФЕ ЛПНБОДХ пРГЙЙ. Й Ч ПФЛТЩЧЫЕНУС ДЙБМПЗЕ пРГЙЙ ПФНЕФШФЕ РХОЛФ уЛБОЙТПЧБФШ ОЕУЛПМШЛП УФТБОЙГ. ч НОПЗПУФТБОЙЮОЩИ PDF- Й TIFF-ЖБКМБИ НПЦОП ПФЛТЩФШ ОЕ ЧУЕ УФТБОЙГЩ, Б ФПМШЛП ФЕ, ЮФП ОХЦОЩ ЧБН. дМС ЬФПЗП ХЛБЦЙФЕ ОПНЕТБ (ЙМЙ ДЙБРБЪПОЩ) УФТБОЙГ, ТБЪДЕМСС ЙИ ЪБРСФПК, ОБРТЙНЕТ: 1,2,8-12.
дБМЕЕ, УПУЛБОЙТПЧБООПЕ ЙЪПВТБЦЕОЙЕ (ЙМЙ ЙЪПВТБЦЕОЙС) ОЕПВИПДЙНП ТБУРПЪОБФШ. тБУРПЪОБФШ НПЦОП ЛБЛ ФЕЛХЭЕЕ ЙЪПВТБЦЕОЙЕ, ФБЛ Й ЧУЕ ЙЪПВТБЦЕОЙС, ЧЧЕДЕООЩЕ Ч ТБНЛБИ ДБООПК УЕУУЙЙ Ч РТПЗТБННХ УП УЛБОЕТБ.
рТЙ ЬФПН РПНОЙФЕ, СЪЩЛ ТБУРПЪОБЧБОЙС ДПМЦЕО УППФЧЕФУФЧПЧБФШ СЪЩЛХ, ОБ ЛПФПТПН ОБРЙУБО ДПЛХНЕОФ. дМС НОПЗПСЪЩЮОЩИ ДПЛХНЕОФПЧ НПЦОП ХЛБЪБФШ ОЕУЛПМШЛП СЪЩЛПЧ. пДОБЛП ОЕ ТЕЛПНЕОДХЕФУС ЧЩВЙТБФШ ВПМЕЕ ДЧХИ-ФТЈИ СЪЩЛПЧ.
рПМШЪПЧБФЕМЙ, ЦЕМБАЭЙЕ ТБУРПЪОБЧБФШ Й ТБВПФБФШ ФПМШЛП У ФЕНЙ УЕЗНЕОФБНЙ ДПЛХНЕОФБ, ЛПФПТЩЕ ОХЦОЩ ЙН, НПЗХФ ЧПУРПМШЪПЧБФШУС ЛОПРЛПК

рТПЧЕТЛХ НПЦОП ПУХЭЕУФЧЙФШ ЧТХЮОХА, РПМШЪХСУШ ЧУФТПЕООЩН WYSIWYG-ТЕДБЛФПТПН, ЛПФПТЩК ПВЕУРЕЮЙЧБЕФ НБЛУЙНБМШОП ФПЮОПЕ ЧПУРТПЙЪЧЕДЕОЙЕ ЧУЕИ ДЕФБМЕК ПЖПТНМЕОЙС ДПЛХНЕОФБ: ЛПМПОЛЙ ФЕЛУФБ, ФБВМЙГЩ Й ЛБТФЙОЛЙ ПФПВТБЦБАФУС Ч ПЛОЕ ТЕДБЛФПТБ ФПЮОП ФБЛ ЦЕ, ЛБЛ ПОЙ ВЩМЙ ТБУРПМПЦЕОЩ ОБ ЙУИПДОПН ЙЪПВТБЦЕОЙЙ.
фБЛЦЕ НПЦОП ЧПУРПМШЪПЧБФШУС ДЙБМПЗПН рТПЧЕТЛБ, Ч ЛПФПТПН РПЛБЪЩЧБЕФУС УМПЧП У ПЫЙВЛПК, ЕЗП ЙЪПВТБЦЕОЙЕ ОБ ЙУИПДОПН ДПЛХНЕОФЕ Й ЧБТЙБОФЩ ЪБНЕОЩ. рТЙ ЬФПН УМЕДХЕФ ХЮЙФЩЧБФШ, ЮФП РПДУЧЕЮЙЧБАФУС Й ПФПВТБЦБАФУС Ч ДЙБМПЗЕ ФЕ УМПЧБ, Ч ЛПФПТЩИ ЕУФШ ОЕХЧЕТЕООП ТБУРПЪОБООЩЕ УЙНЧПМЩ, ФП ЕУФШ ФБЛЙЕ, ДМС ЛПФПТЩИ ПГЕОЛБ ХЧЕТЕООПУФЙ УБНПК МХЮЫЕК ЗЙРПФЕЪЩ ЙЪ ЧУЕИ, ЧЩДЧЙОХФЩИ УЙУФЕНПК, НЕОШЫЕ ОЕЛПЕЗП ЪБДБООПЗП ХТПЧОС. чПЧУЕ ОЕ ЖБЛФ, ЮФП ОЕХЧЕТЕООП ТБУРПЪОБООЩЕ УЙНЧПМЩ — ПЫЙВПЮОЩ.
дМС ФПЗП, ЮФПВЩ УПИТБОЙФШ ТЕЪХМШФБФЩ ТБУРПЪОБЧБОЙС Ч ЖБКМ, ОБЦНЙФЕ ОБ УФТЕМЛХ УРТБЧБ ПФ ЛОПРЛЙ уПИТБОЙФШ Й ЧЩВЕТЙФЕ ЛПНБОДХ уПИТБОЙФШ УФТБОЙГЩ. тБУРПЪОБООЩК ФЕЛУФ НПЦОП УПИТБОЙФШ Ч УМЕДХАЭЙИ ЖПТНБФБИ: RTF, DOC, Word XML, XLS, PDF, HTML, PPT, TXT, DBF, CSV, LIT.
тБЪХНЕЕФУС, НПЦОП РЕТЕДБФШ ТБУРПЪОБООЩК ДПЛХНЕОФ Ч УППФЧЕФУФЧХАЭЕЕ РТЙМПЦЕОЙЕ, ЮФПВЩ РТПДПМЦЙФШ ТБВПФХ У ОЙН У ЙУРПМШЪПЧБОЙЕН РТЙЧЩЮОЩИ ЙОУФТХНЕОФПЧ.
дМС ЛБЦДПЗП ЖПТНБФБ НПЦОП ЧЩВТБФШ ОБУФТПКЛЙ УПИТБОЕОЙС. пОЙ ОБИПДСФУС ОБ УППФЧЕФУФЧХАЭЕК ЪБЛМБДЛЕ ДЙБМПЗБ жПТНБФЩ (ОБУФТПКЛЙ ЖПТНБФБ PDF ОБИПДСФУС ОБ ЪБЛМБДЛЕ PDF Й Ф.Д.). дМС ФПЗП ЮФПВЩ ПФЛТЩФШ ДЙБМПЗ жПТНБФЩ, ОБЦНЙФЕ ОБ УФТЕМЛХ УРТБЧБ ПФ ЛОПРЛЙ уПИТБОЙФШ, ЧЩВЕТЙФЕ ЛПНБОДХ пРГЙЙ. Й Ч ПФЛТЩЧЫЕНУС ДЙБМПЗЕ ОБЦНЙФЕ ЛОПРЛХ жПТНБФЩ.
нПЦЕФ ВЩФШ ЧУЕ ПРЙУБООПЕ ЧЩЫЕ Й ОЕ РТЕДУФБЧМСЕФУС УФПМШ ХЦ ОПЧЩН, ОП ЧПФ ОБ 2-И НПНЕОФБИ ИПЮХ ПУФБОПЧЙФШУС
1. ч ABBYY FineReader НПЦОП УРПЛПКОП, ЙНЕС ЖБКМ Ч ЖПТНБФЕ pdf, РТЕПВТБЪПЧБФШ ЕЗП, ОБРТЙНЕТ Ч word, ДМС ДБМШОЕКЫЕЗП ТЕДБЛФЙТПЧБОЙС. (оБРТЙНЕТ, ЧЩ УЛБЮБМЙ ЙЪ ЙОФЕТОЕФБ ЖБКМ, Б ПО ПЛБЪБМУС Ч pdf ЖПТНБФЕ, Б ЧБН ОХЦОП ЧЩФБЭЙФШ ЙЪ ОЕЗП ФЕЛУФ, ЙМЙ ФБВМЙГХ, ЙМЙ ЕЭЕ ЮФП ). дМС ЬФПЗП ОХЦОП ЪБРХУФЙФШ FineReader -> ЧЩВТБФШ жБКМ -> пФЛТЩФШ pdf ЙЪПВТБЦЕОЙЕ -> ЧЩВЙТБЕФЕ ЧБЫ ЖБКМ У ТБУЫЙТЕОЙЕН pdf -> РТПЙЪЧПДЙФЕ ЕЗП ТБУРПЪОБЧБОЙЕ -> УПИТБОСЕФЕ ЕЗП Ч word — Й НПЦЕФЕ ТЕДБЛФЙТПЧБФШ РП УЧПЕНХ ХУНПФТЕОЙА
2. оЕ НОПЗЙЕ ЪОБАФ, ЮФП Ч FineReader (ФПМШЛП ОЕ Ч ДЕНП-ЧЕТУЙЙ) ЕУФШ ЧУФТПЕООБС ХФЙМЙФБ Screenshot Reader. пОБ РТЕДОБЪОБЮЕОБ ДМС ТБУРПЪОБЧБОЙС ФЕЛУФБ УП УОЙНЛПЧ ЬЛТБОБ ЧБЫЕЗП НПОЙФПТБ. тБВПФБЕФ ПОБ РП РТПУФПНХ РТЙОГЙРХ: УОБЮБМБ ЧЩРПМОСЕФУС УОЙНПЛ У ЬЛТБОБ (ДБООБС РТПГЕДХТБ — БОБМПЗ ДЕКУФЧЙС ЛМБЧЙЫЙ PrintScreen), РПУМЕ ЮЕЗП FineReader «РПДОЙНБЕФ» ЬФП ЙЪПВТБЦЕОЙЕ ЙЪ ВХЖЕТБ ПВНЕОБ Й ТБУРПЪОБЕФ ФЕЛУФЩ, ФБВМЙГЩ Й ДТХЗЙЕ УФБОДБТФОЩЕ ПВЯЕЛФЩ ДПЛХНЕОФПЧ. фП ЦЕ УБНПЕ НПЦОП УДЕМБФШ Й ЧТХЮОХА, ОП Screenshot Reader РПЪЧПМСЕФ ЪОБЮЙФЕМШОП УЬЛПОПНЙФШ ЧТЕНС. п ЧПУФТЕВПЧБООПУФЙ РПДРТПЗТБННЩ НПЦОП УРПТЙФШ, ОП ВЕУРПМЕЪОПК ЕЕ ОБЪЧБФШ ОЕМШЪС. чП-РЕТЧЩИ, ПОБ ЪОБЮЙФЕМШОП ЬЛПОПНЙФ ЧТЕНС, ЧП-ЧФПТЩИ, ЬФП ПДЙО ЙЪ ОЕНОПЗЙИ УРПУПВПЧ «ДПУФБФШ» ЙУИПДОЩК ФЕЛУФ ЪБЭЙЭЕООЩИ ФЕЛУФПЧЩИ ЖБКМПЧ Й ДПЛХНЕОФПЧ.
ъБРХУЛБЕФУС ПОБ РТПУФП: рХУЛ -> рТПЗТБННЩ -> ABBYY FineReader -> ABBYY Screenshot Reader.
чОЕЫОЙК ЧЙД РТПЗТБННЩ РТПУФ ДП ВЕЪПВТБЪЙС

рТЙ ОБЦБФЙЙ ОБ ЛОПРЛХ РПСЧМСЕФУС УЕФЛБ ЪБИЧБФБ, чЩ НПЦЕФЕ ЧЩДЕМЙФШ ПВМБУФШ ОБ ЬЛТБОЕ НПОЙФПТБ ДМС ДБМШОЕКЫЕЗП ЕЗП ЛПРЙТПЧБОЙС Л УЕВЕ ОБ ЛПНРШАФЕТ Ч ЧЙДЕ ЖБКМБ (ЙМЙ У ЪБОЕУЕОЙЕН Ч ВХЖЕТ ПВНЕОБ).
рПЬЛУРЕТЙНЕОФЙТХКФЕ У ЬФЙН, Й ОБЧЕТОСЛБ ЧБН ЬФП РПОТБЧЙФУС
Конспект лекции на тему: «Возможности программы FineReader. Технология распознавания. Распознавание текста».
КОНСПЕКТ ЗАНЯТИЯ
Тема занятия: Возможности программы FineReader. Технология распознавания. Распознавание текста.
Цель занятия : Изучить возможности программы FineReader. Технология распознавания.
ABBYY FineReader — программа для мгновенного распознавания цифровых изображений и PDF-файлов любых типов с возможностью преобразования результатов в наиболее популярные электронные форматы DOC, XLS, RTF, PPT, HTML, PDF, PDF/A, CSV, TXT и DJVU.
ABBYY — мировой флагман технологий оптического распознавания, разработчик программ и сервисов лингвистической поддержки. Популярные словари, разговорники и онлайн-переводчики ABBYY Language Services, ABBYY Lingvo , ABBYY PDF Transformer – всё это продукты компании АББИ. Но добилась наибольшего признания и получила самое широкое распространение программа для распознавания текста из результатов сканирования и файлов pdf — Abby Fine Reader, за двадцать пять лет существования став незаменимым помощником для миллионов людей во всём мире.
ABBYY FineReader 12 Professional увеличил скорость распознавания документов в «быстром режиме» на 40%, для ч/б-документов еще на 30%. Он полностью восстанавливает логическую структуру документа и «видит» его как единое целое, что избавляет пользователя от лишнего форматирования. Ознакомительную русскую версию Эбби Файн Ридера скачать бесплатно можно на сайте производителя. В процессе регистрации появится форма где нужно указать e-mail, на который придет ссылка для скачивания, ключ для установки не требуется. Скачать FineReader 12 бесплатно на русском языке можно по ссылке ниже, он поддерживает 190 языков распознавания и может интегрироваться в Windows 8. Размер: 351 МБ.
ABBYY FineReader 10 Home Edition скачать бесплатно на русском и еще на 178 языках можно с официального сайта АББИ. Файн Ридер 10 автоматически корректирует искажение перспективы и исправляет резкость снимков, а технология Digital OCR позволяет распознать фото документов с разрешением более 2 Мп. АББИ Файнридер 10 поддерживает 188 языков распознавания, имеет возможность сохранения результатов сканирования в формате DjVu , действует в течение 15 дней и распознаёт до 50 страниц. Размер: 110 МБ.
ABBYY FineReader Online позволяет распознать до трёх страниц текста бесплатно и купить при необходимости дополнительные, используя удобный способ оплаты – платежную карту PayPal. Если вам нужно распознать лишь одну-две-три страницы или если скорость интернет соединения не позволяет скачать FineReader на компьютер быстро, воспользуйтесь бесплатным облачным сервисом от ABBYY – Файн Ридер онлайн. Регистрация занимает не более двух минут и вы получаете мгновенный доступ ко всем функциям оригинальной программы.
FineReader позволяет ввести документ одним нажатием на кнопку Scan&Read, не вдаваясь в подробности работы программы. Распознанный текст можно передать в текстовый редактор или электронную таблицу, сохранить в форматах PDF и HTML с полным сохранением оформления документа или сохранить в базе данных
В системе FineReader инструментальных панелей всего 4: Стандартная, Изображение, Форматирование и главная панель программы Scan&Read. Кнопки на инструментальных панелях — самое удобное средство доступа к операциям системы. Те же операции можно выполнять из меню программы или с помощью горячих клавиш.
Если Вы хотите узнать о назначении той или иной кнопки на инструментальной панели, установите на ней курсор мыши. Под кнопкой появится подпись (tooltip), а на информационной панели будет выведено более подробное сообщение о назначении этой кнопки.
Главная панель программы — Scan&Read
Кнопки на панели Scan&Read связаны с базовыми операциями системы: Сканирование, Распознавание, Проверка и Сохранение результатов распознавания. Цифры на кнопках указывают, в каком порядке нужно выполнить действия, чтобы получить электронную версию бумажного документа. Каждое из этих действий можно провести по отдельности или объединить в одно, нажав на кнопку Мастер Scan&Read. Она позволяет провести полный цикл обработки текста автоматически. Каждая из кнопок имеет несколько режимов работы. Нажав на стрелку справа от кнопки, в открывшемся локальном меню Вы можете выбрать один из них, при этом «информация» об этом отразится на иконке кнопки. Для того, чтобы повторить ту же операцию для другого изображения, Вам достаточно повторно нажать на кнопку.
На панели Форматирование находятся кнопки, позволяющие изменить оформление текста.
 Панель Изображение содержит кнопки, позволяющие производить анализ макета страницы (например, создать и отредактировать блоки), а также кнопки, позволяющие увеличить/уменьшить масштаб изображения, отредактировать изображение (например, стереть ненужные участки изображения, такие, как подписи или большие участки мусора).
Панель Изображение содержит кнопки, позволяющие производить анализ макета страницы (например, создать и отредактировать блоки), а также кнопки, позволяющие увеличить/уменьшить масштаб изображения, отредактировать изображение (например, стереть ненужные участки изображения, такие, как подписи или большие участки мусора).
На панели Стандартная находятся кнопки, управляющие работой с файлами и изображением (отмена и повтор действия, перемещение по страницам пакета, очистка и поворот изображения), а также список языков распознавания.

