

Что делает программа Abbyy FineReader?
Abbyy FineReader — Файн Ридер скачать бесплатно на русском
Abbyy FineReader – это широко известная программа для сканирования документов и распознавания текста. На сегодняшний день она является наиболее популярной благодаря понятному и удобному интерфейсу, большому набору всевозможных функций, связанный со сканированием и работой с готовым документом, а также удобством в использовании.

При помощи программы Файн Ридер можно:
Сканировать любой документ через ваш сканер и после распознать и сохранить для дальнейшего редактирования на компьютере, отправить по электронной почте, сохранить на флешке и т.д. Так же можно переводить изображения, сканы, PDF-файлы, фотографии в другие форматы, например, конвертировать их в таблицы и тексты без необходимости набирать текст заново. При этом распознаются многие форматы изображений, а форматирование текста часто остаётся не тронутым.
Файн Ридер программа для сканирования документов умеет работать со всеми сканерами включая самые популярные такие как Canon (Кэнон), HP, Kyocera (Куосера), Samsung (Самсунг) и другие.

Программа для сканирования может сохранить документ в редакторы — Word (Ворд), Excel (Эксель), OpenOffice, Adobe Acrobat а так же экспортировать файлы в облачные хранилища по вашему выбору.
| Название | Язык | Рейтинг: | Загрузки | |
 |
Abbyy FineReader 10 | На Русском | Хорошо 8/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 11 | На Русском | Очень хорошо 9.7/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 12 | На Русском | Очень хорошо 9.7/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 14 | На Русском | Очень хорошо 9.8/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 15 | На Русском | Очень хорошо 9.8/10 |
Скачать бесплатно >> |
Помимо широкого функционала эта программа для скана выпускается более, чем на 170 языках мира, в том числе и на русском. Скорость и эффективность работы, особенно в самой новой версии Abbyy FineReader, удивительны. А улучшенный редактор изображений позволяет сделать предварительную обработку сканов и фотографий.
Можно по своему желанию добавить или снизить яркость и контрастность, скорректировать погрешности, допущенные камерой. Это позволит как можно точнее распознать текст и области рисунков. Удобный и понятный даже впервые столкнувшемуся с программой человеку интерфейс, делает её незаменимым помощником как на рабочем месте, так и дома.
Как сканировать и распознать документ:
Если программа на русском все достаточно просто и понятно, версия скачанная с нашего сайта бесплатна.
На верхней панели достаточно большие значки основных функций, на скрине ниже 11 версия но и в других все примерно одинаково изменены лишь сами значки.
Для того чтоб распознать нужно сначала сканировать со сканера документ либо загрузить картинку например с текстом, после нажать на кнопочку Распознать.

После распознания и корректировки можно сохранять документ в редактируемый а также желаемый формат например ПДФ (PDF).

Настройки Файн Ридер программы:
При обычном использовании например только распознать или только сканировать углубленные настройки вообще не нужны.
Если все же вам необходимы доп. настройки то нажмите Сервис -> Опции. (для версии 11)
Из углубленных функций можно воспользоватся редактором языков если у вас текст который нужно распознать не Русский.
Укрощение строптивого (на самом деле, нет) FineReader
- На пути к профессиональному использованию современных OCR. Understanding FineReader
- Этот пост
После короткого рассказа о том, как устроен ABBYY FineReader (aka «теоретическая часть»), самое время перейти к применению полученных знаний. И да, котиков под катом нет: всё очень серьёзно.
Как пользователю поучаствовать в обработке документа
Чтобы не изобретать велосипед, начну с простой и понятной схемы из Справки (см. рисунок справа).
Теперь, зная список всех операций, посмотрим на примерах – что может пойти не по плану и как с этим бороться.
Хорошо распознаются только хорошие изображения
А что делать, когда изображения есть, но не очень хорошие? Улучшить прямо в FineReader всё что можно, а, если улучшить нельзя, — попытаться получить изображение заново, устранив проблему. Поскольку тема очень обширная, то при должном интересе будет отдельный пост про то, как подружиться с автоматическими и ручными инструментами обработки изображений прямо в FineReader. Пока же ограничусь замечанием, что изображение будет обработано лучше, если оно:
- (после сканирования) не имеет выраженных геометрических искажений — перекоса или заметного изгиба страниц толстой книги у корешка двухстраничного разворота,
- (после фотографирования, в дополнение к предыдущему) не имеет ещё и нелинейных геометрических искажений («подушка», «трапеция»), имеет равномерную фокусировку (а желательно и яркость) по всей площади, не имеет шумов от недостаточной освещённости, не имеет выраженной засветки от вспышки (особенно на глянцевой бумаге).
Этап настройки документа/проекта
Можно и нужно сразу указать язык текста, параметры предобработки изображений, некоторые параметры анализа и распознавания. Вот скриншот одной из вкладок диалога настроек. 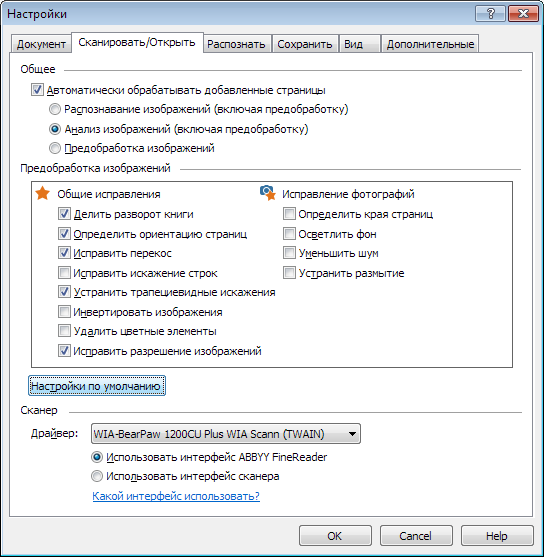
Эти и прочие настройки подробно описаны в Справке
Этап анализа
Программа автоматически выделяет области различных типов с точки зрения распознавания. На этом этапе мы можем как самостоятельно разметить области, так и поправить (при необходимости) те, что нашёл модуль Анализа.
Чтобы не писать много лишнего про инструменты работы с областями, сошлюсь на раздел Справки, а здесь объясню, что для чего, «что такое хорошо, что такое плохо» (применительно к областям) и как исправить плохой результат.
Назначение областей разных типов
В пользовательском интерфейсе FineReader доступны области нескольких типов, для них есть разные варианты скрываемой панели свойств (внизу окна «Изображение») и контекстного меню (по щелчку правой кнопкой мыши):
-
«Зона распознавания» (по умолчанию серая рамка) — такое название использовано в пользовательском интерфейсе, на мой взгляд правильнее было бы назвать «область для автоматического анализа». Назначение такой области – указать, где на странице вообще нужно искать что-то полезное. Поэтому в результате последующего анализа или анализа+распознавания в пределах каждой «зоны распознавания» может найтись ноль и более областей других типов. Особенно полезны зоны распознавания бывают в шаблонах блоков (подробнее о них в Справке).
Текстовая область – содержит текст одной и более строк, каждая из которых содержит логически связный текст, поэтому выделять две колонки в один блок – очень плохая идея. Может иметь непрямоугольную форму. Бывает нужно задать или поправить после неверного определения автоанализом направление текста, «инверсность» (упрощённо: тёмный текст на светлом фоне — «обычный текст», а светлый текст на тёмном фоне – «инверсный» текст, по умолчанию установлена в «Авто» и почти никогда не требует коррекции).
Эти параметры задаются на блок, так что выделять текст разного направления или разной инверсности в один блок – другая плохая идея.
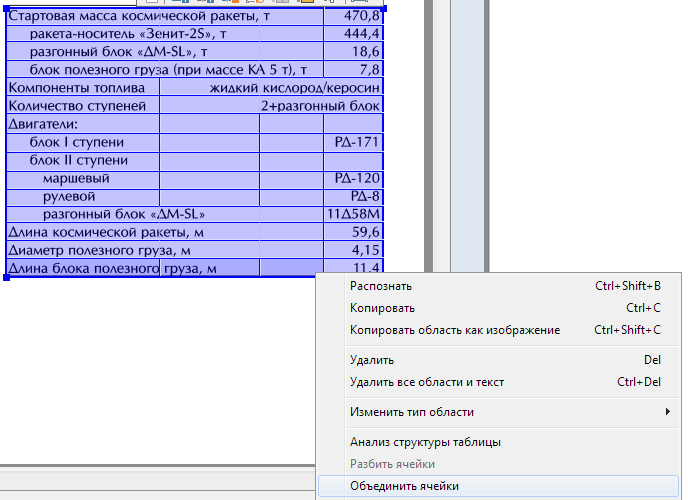 Табличная область – содержит таблицу, как с видимыми разделителями строк и столбцов, так и невидимыми (частично или везде). Таблица может иметь только прямоугольную форму, каждая из ячеек тоже является прямоугольником, но используя объединение групп ячеек или групп строк, можно передавать весьма сложные конфигурации текста.
Табличная область – содержит таблицу, как с видимыми разделителями строк и столбцов, так и невидимыми (частично или везде). Таблица может иметь только прямоугольную форму, каждая из ячеек тоже является прямоугольником, но используя объединение групп ячеек или групп строк, можно передавать весьма сложные конфигурации текста.
В каждой ячейке может быть распознаваемый текст (возможно, пустой) или картинка. Если вы хотите распознавать текст в ячейке, то можно задать ему особые параметры распознавания, а если нет, то стоит указать «картинка во всю ячейку». Кстати, можно выделить сразу прямоугольную группу ячеек таблицы и изменить нужное свойство у всех сразу.
Таблицы — сложный объект для автоматического анализа, особенно при частично или везде невидимых разделителях. Чрезвычайно важно, что вручную исправить расположение и разметку таблицы до первого или повторного распознавания всегда проще, чем исправлять неверную структуру текста уже после распознавания — в FineReader или даже после сохранения, в целевом приложении. Так что в разделе «Практикум» я приведу очень много примеров из реальной жизни исправления ошибок автоматической разметки таблиц.
Важные соображения
- Распознавание и синтез видят только те фрагменты текста, которые оказались выделены в текстовые области или текстовые ячейки таблиц. Если кусок текста не выделен в блоки – распознаваться он не будет.
- Аналогично и с картинками — если часть картинки оказалась вне области или одна целостная картинка оказалась разделена на несколько областей – скорее всего, в результате обработки будут проблемы.
- Языки распознавания в FineReader задаются не для галочки – они влияют на очень многие механизмы, начиная уже с анализа: например, иероглифический (китайский, японский, корейский языки) или арабский текст имеют много особенностей, которые учитываются не всегда, а только при выборе соответствующих языков распознавания.
Особенности взаимодействия близкорасположенных или пересекающихся областей
Следующие правила важны как для правильного обращения с областями в оболочке программы, так и для понимания — что с ними получится в результатах распознавания и сохранения.
-
Пересечение текстовых и табличных блоков друг с другом, если есть символы или их части, оказавшиеся в более чем одном блоке – практически всегда ошибка, такие результаты анализа нужно исправлять, тем более что обычно это делается в несколько движений мыши.
Пересечение картиночных областей друг с другом – практически всегда ошибка, хотя и менее критичная для обработки именно текста. Такие случаи тоже желательно исправлять.
Картиночная область на фоне большей текстовой области – законное и нередко востребованное сочетание. Основное применение – обработка так называемых inline-картинок, когда внутри строки (или между строк) встречается фрагмент (пиктограмма, формула или её часть и т.п.), который плохо распознаётся или совсем не распознаётся в используемой в FineReader модели текста.


Текстовая область на фоне «картиночной» области — тоже важный инструмент: на фоне обычных картиночных областей могут находиться подписи к ним, на «фоновых» картиночных областях может располагаться и основной («колоночный») текст документа, а также таблицы.
Маленькие хитрости для облегчения работы с блоками
Описанные соглашения отражены в поведении редактора блоков. Например, если вы рисуете новый или растягиваете имеющийся блок так, что он полностью или почти полностью перекрывает другие блоки — эти другие блоки автоматически удаляются.
Логичность/нелогичность выделения областей
Тут самое время подумать — для каких целей и какого формата документ хочется получить в результате обработки. Вот некоторые соображения, влияющие на количество и характер исправлений разметки блоков в сложных случаях:
Вариант 1: нам нужен только текст (возможно, мы этого не понимаем, но дело обстоит именно так)
Если нужно сохранить документ в PDF с изображениями страниц исходного документа и добавленным «невидимым» распознанным текстом (для его поиска и копирования), то главное – обеспечить разумное выделение текста в текстовые и табличные блоки. Под «разумностью» здесь понимается следующее:
- нет «мусорных» областей, где в качестве текста или таблиц распознаются (мусором) элементы картинок или элементов оформления страницы.
- области логично выделяют строки, не допуская попадания символов в более чем одну область и неоправданного дробления строк на более чем одну область.
- то, что с точки зрения человека является таблицами в оригинале, должно быть выделено в табличные области. Это влияет как на качество распознавания (например, базовые линии строк в разных ячейках могут быть не выровнены по вертикали), так и на удобство поиска и копирования фрагментов текста в выходном документе.
Если отдельные картинки не должны копироваться из выходного PDF-документа – то такие области можно из документа исключить вовсе (не создавать новые и не оставлять найденные автоматикой, как минимум – удалять нелогично найденные картинки, а если не лень – то и все).
Я надеюсь шире и глубже раскрыть тему «разумности» картинок в статье про сохранение документов — если такая будет интересна читателям данного материала.
Вариант 2: нужно всё и сразу
Если документ, включающий не одно лишь текстовое содержимое (в одну или две колонки), предполагается сохранить сразу как электронную книгу в форматах FB2/e-pub или в любой промежуточный редактируемый формат (Вордовый или HTML) для дальнейшего редактирования и производства электронной книги, то осмысленное выделение таблиц и картинок становится особенно важно.
Среди прочего нужно определиться с тем, что делать с группами рядом расположенных картинок, и что делать с подписями к картинкам, как рядом стоящими, так и накладывающимися на картинки. Подробнее разберём эту тему в «Практикуме», на реальных примерах.
Обзор ABBYY FineReader Pro. Профессиональная система оптического распознавания текста пришла на Mac

Компания ABBYY всегда у меня ассоциировалась со словарями Lingvo и с системой оптического распознавания текста FineReader. Уверен, что у студентов, поступивших в вуз в 90-е, те же самые ассоциации. Сканер и принтер — первые периферийные устройства для ПК учащегося. А там, где есть сканер, обязательно было установлено и приложение FineReader, так как этот инструмент по праву считается лучшим в своей области. Но, что самое главное, разработчик продолжал его улучшать из года в год, хотя в первую очередь поддерживалась платформа Microsoft Windows из-за своей массовости, пользователям OS X приходилось довольствоваться малым. Тем не менее, с ростом популярности Mac, начал расти и ассортимент специализированных приложений. Естественно, ABBYY не осталась в стороне.
Очень похожая ситуация была и с системами проверки русской грамматики и орфографии, когда даже MS Office для Mac не обладал соответствующими инструментами, тогда как в версии для Windows они были. Но, как мы знаем, в 2010 году проблема была частично решена, а спустя еще несколько месяцев она пропала в принципе.
Аналогично и в тех же временных рамках изменялась ситуация и с продуктами ABBYY. В 2010 году компания выпустила Lingvo для Mac и примерно в то же время для OS X появилось приложение FineReader Express. Оно получило престижную награду Macworld Awards 2010 в номинации «Лучшее профессиональное ПО», но по своим возможностям все-таки оказалось слабее версии FineReader Pro, которая на тот момент была доступна только для Windows. Первая предоставляла базовые возможности оптического распознавания текстов и работала с небольшими документами. Для второй объем документа значения не имел, да и точность распознавания была выше. Но теперь ABBYY FineReader Pro доступна и для Mac, а значит, о виртуальной машине или Boot Camp можно забыть, если таковые использовались для запуска Windows-версии профессионального пакета. Что ж, давайте взглянем на его возможности в версии для OS X.
Что умеет FineReader Pro для Mac

Стоит отметить, что в основе профессионального Mac-варианта FineReader лежит новейшая версия с порядковым номером «12», то есть она включает в себя не только дополнительные возможности Pro-пакета, но и ряд важных нововведений. Например, увеличено количество языков распознавания со 171 до 189. Помимо основных европейских языков появилась поддержка китайского, японского, корейского, тайского, вьетнамского, арабского и иврита. Причем FineReader Pro автоматически определяет язык текста и корректно распознаёт комбинированные документы с любым количеством поддерживаемых языков.
Вторая из важнейших Pro-функций — это точное восстановление структуры и форматирования документа. За данную возможность отвечает оригинальная технология ADRT (Adaptive Document Recognition Technology), которая анализирует логическую структуру документа и точно восстанавливает ее в электронной копии. Если говорить простым языком, то таблицы, списки, заголовки и прочие элементы бумажных документов будут перенесены в электронную копию автоматически, и вам не придется долго и нудно доводить документ до кондиции руками. Помнится, в прошлом у меня бывали случаи, когда пытаясь упростить себе работу, сканировал документ, а потом тратил уйму времени на воссоздание таблиц и списков. Наверное, в тех случаях даже быстрее было бы все сразу сделать вручную. Теперь такой проблемы нет.
Более того, речь идет не только об отдельных элементах, упомянутых выше (таблицы, списки и т. п.), но и о форматировании документа (шрифт, его кегль, стиль, отступы, абзацы и прочее).
Значительно повышена точность оптического распознавания символов в сравнении с предыдущей упрощенной версией FineReader и увеличено количество форматов для сохранения результатов распознавания. Помимо RTF, TXT, XLS, PDF (с возможностью поиска) и HTML появилась поддержка DOCX, ODT, XLSX (электронная таблица), PPTX (презентация), PDF/A (формат для долгосрочного хранения), EPUB и FB2 (форматы электронных книг), CSV.
Кстати, у читателя может возникнуть крамольная мысль о том, что сканер или же МФУ (гибрид типа сканер+принтер+ксерокс) — это удел офисов, и дома такой аппарат уже и не найти, а покупать как-то не охота. Но ведь практически у каждого есть мобильный телефон или смартфон со встроенной фотокамерой. Это тот же сканер, разве что не столь удобный в использовании, и FineReader Pro умеет отлично работать с изображениями, полученным с мобильных устройств и фотокамер. Причем программа даже обладает встроенным редактором, позволяющим нивелировать минусы использования фото, когда снимок получается нечетким, неконтрастным и, что самое неприятное, снят под углом.


Кликабельно
Вам не придется беспокоиться о входном формате изображения, так как поддерживаются все основные (PDF, TIFF, JPEG, JPEG 2000, PNG, BMP, GIF, PCX, DCX) и даже экзотические (JBIG, JBIG2 — поддержка реализована только в Pro-версии). Результат распознавания можно сохранить не только в виде электронного документа, но и изображений тоже (TIFF, JPEG, JPEG 2000, PNG, BMP, PCX, DCX, JBIG2).
Что ж, давайте испытаем приложение в действии.
Опыт работы с ABBYY FineReader Pro для Mac
Программа обладает удобным и очень простым интерфейсом. Вспоминая версии FineReader 5.x, 6.x для Windows, прогресс просто удивляет. К тому же в данном случае это не калька Windows-варианта, а интерфейс, разработанный специально для Mac со всеми его особенностями, включая поддержку полноэкранного режима.
Установка приложения в OS X традиционно легкая — достаточно перетащить иконку в папку «Applications» (попадет в «Приложения»):

После запуска FineReader Pro появляется простое меню, с выбором наиболее часто используемых задач:

Один клик, и вы попадете в меню расширенных опций:

Работать с приложением просто, будь то распознавание через сканер…

…Или же использование изображения, снятого с помощью мобильного телефона:

Причем в последнем случае я буквально в один клик выровнял картинку, еще пара нажатий — и убраны лишние поля, затем клик на кнопку «Распознать», после чего программа определила, где находится текст, а где изображения:

Если контент был определен не очень точно (например, мелкий текст был выделен не полностью или же определена лишь часть фоновой картинки), то с помощью инструмента «Инспектор» можно в несколько кликов указать нужный контент и скорректировать границы распознавания того или иного объекта. Это я и сделал выше, подкорректировав область с нижним текстом и выделив весь документ в качестве фоновой картинки. А вот и результат:

Я сохранил его в PDF-документе и, как видите, текст можно выделить и скопировать:

Конечно, есть ошибки в распознавании, но это ОЧЕНЬ сложный пример из-за цветного фона, и даже в таком случае программа справилась хорошо.
Еще пара примеров с другими документами попроще:


Кликабельно
Результат можно править в PDF-редакторе, либо сохранить в любом другом из упомянутых выше форматов и работать с электронной копией документа используя привычные приложения.

При необходимости, результат легко отправить через E-mail прямо из меню FineReader Pro. Приложение уже доступно в Mac App Store и обойдется в 3290 руб.
Работать с программой действительно комфортно и каких-то особых спецнавыков не требуется — разберется любой пользователь Mac. А ведь это профессиональный инструмент, позволяющий работать с документами любой сложности и распознающий под 200 языков мира! Это удивительно и невероятно на фоне того, что мы имели буквально 5–10 лет назад.
Профессиональные приложения существовали во все времена эры ПК, но о юзабилити в прошлом речи не шло. Главное — результат, а то, что для его получения придется прорываться через дебри меню, а то и писать свой код — это никого не волновало, да и вычислительные возможности компьютеров оставляли желать лучшего. Их нехватка заменялась, что называется, ручным трудом.
Теперь же буквально в несколько кликов вы можете бумажный документ превратить в электронный, создав фактически его точную копию, которую можно редактировать. И это лишь одна из областей, где применяется вся мощь современных достижений в IT-сфере. Но ведь таких областей много — обработка фото, монтаж видео, создание и обработка музыки. Прогресс впечатляет и возбуждает. Особенно, если задуматься о том, что будет еще через 5–10 лет при таких же темпах развития.
- Твитнуть
- Поделиться
- Рассказать
- Apple,
- полезный в быту софт
Роман Юрьев
Дотошный блогер, гаджетоман, лысый и бородатый фитнес-методист. Увлекаюсь технологиями, спортом и диетологией.
ABBYY FineReader 15 + ключ активации лицензионный 2021
Abbyy FineReader отлично подойдет для быстрой работы с сфотографированным текстом, оцифровки старых печатных изданий и даже перевода конспектов в электронный вид. Этот продукт российской компании ABBYY начиная с 2009 года удостаивался различных премий: «Лучший софт», «Лучшее профессиональное ПО» и проч.
Она позволяет быстро и качественно получить текст из отснятых или отсканированных документов, не меняя последовательности страниц в документе и их структуры. Полученный документ можно сохранять в разных форматах, просматривать, редактировать, искать по содержимому и прикреплять к электронным письмам. 
ABBYY FineReader: что это за программа
В основу FineReader Professional Edition положена технология OCR, заключающаяся в следующем: программа не подбирает загруженное в нее изображение символа, сравнивая с, возможно, бесчисленным множеством шаблонов в поисках подходящего, а делает несколько предположений, на что похож данный оптический объект, что это за знак, постепенно проверяя их.
Затем программа для сканирования выбирает наиболее похожий символ и ищет у исходного сходства с ним. Кроме того, программа способна самообучаться: оцифровывать части документа, опираясь на предыдущий опыт работы с этим же документом. К примеру, седьмая глава отсканированной книги будет обрабатываться несколько быстрее, чем первая, именно за счет обучаемости софта.
Необязательно загружать отсканированные файлы – достаточно будет фотографии с телефона или фотоаппарата(минимально допустимые характеристики – 2МП + автофокус), которую затем можно отредактировать во встроенном редакторе изображений. Кроме того, в ней можно сделать снимок части экрана – screenshot.
Продукт поддерживает более 190 языков, из которых в 48 встроена поддержка орфографии; используемые в файле языки можно настроить заранее или позволить определить самостоятельно. Также вручную можно задать тип обрабатываемого участка: рисунок, таблица, текст. При помощи технологии ADRT сохраняется не только исходная структура документа – нумерация страниц, оглавление, примечания – но даже расположение на странице текста и таблиц.
Для устройств под управлением windows 7 и windows 10 основные задачи(сценарии) доступны прямо из главного окна. А для системы windows 8 в дополнение к ним поддерживаются базовые жесты для сенсорных устройств, такие как масштабирование и прокрутка. В процессе работы можно выбрать, что важнее в данном конкретном случае: скорость или качество работы, и экономить до 50% времени.
С какими форматами работает?
В большинстве случаев Файн Ридер используется для работы с форматом PDF, однако он способен сохранять обработанные файлы не только в нем:
- RTF.
- DOC.
- DOCX.
- DJVU.
- ODT.
- PPT.
- TXT.
- DBF.
- CSV.
- LIT.
- Fb2.
- Epub.
- Создавать HTML-документы.
Кроме того, его можно запускать прямо из пакета Microsoft Office(Excel,Word,Outlook) и сохранять готовые документы в облако. На примере это можно рассмотреть так: документ, высланный вам по почте, находится в формате PDF. Вы откроете его в FineReaderе, распознаете и преобразуете в word-файл, отредактируете как вам необходимо, и сохраните в формате пакета OpenOffice Writer – ODT. Или снова в PDF или оставите в DOC.

Установка
Установщик предоставляется бесплатно и без регистрации. После скачивания файла вы увидите в папке загрузки текстовый документ README.txt и приложение ABBYY.FineReader.v12.0.101.496.exe.

Закройте все окна Microsoft Office. Запустите установчник 

Выберите адрес каталога, куда нужно будет установить программу, «обычный» режим установки

и необходимые опции перед началом установки: рекомендуется убрать галочки во всех строках, кроме второй: «Создать ярлык для ABBYY FineReader 12 на рабочем столе».

После этого ждите окончания процесса. Установка обычно занимает около 10 минут, но не завершайте процесс, не дождавшись окончания: на «засоренном» компьютере она может длиться до получаса или часа.

После появления окна, сообщающего о завершении установки, нажмите кнопку «готово», и программой можно пользоваться – ключик активации уже встроен в файлы.

Интерфейс
Последняя версия ABBYY FineReader 12 обладает дружелюбным пользователю интерфейсом. Верхняя строка разделена на вкладки:
- Файл
- Правка
- Вид
- Документ
- Страница
- Область
- Сервис
- Справка

Основная используемая вкладка «Файл» содержит в себе опции «Новая задача», «Сканировать страницы», «Открыть PDF или изображение», «Сохранить документ», «Отправить по электронной почте», «Печать» и т.д. 
По умолчанию при старте приложения открывается окно «Задача»

Которое также можно вызвать одноименной кнопкой в верхней левой части экрана. В подпунктах можно выбрать одну из стандартных задач – конвертирование, создание электронных таблиц и т.п.- или создать свою пользовательскую задачу.
Слева находится вертикальный список из нескольких пунктов – смотря с чем необходимо работать:
- «Основные» — отображает наиболее популярные действия, такие как быстрое сканирование, сканирование в PDF и Microsoft Word;
- «Microsoft Word», «Excel», Adobe PDF — здесь показываются действия-связки Файнридера и Ворда, Экселя, PDF соответственно, например, «Сканировать в..»;
- В пункте «Другие» находятся кнопки сканирование в прочие и редко используемые форматы: HTML,EPUB и т.д;
- В «Моих задачах» можно создать персонально-ориентированную задачу, облегчающую повседневную работу.
Выбор языка для работы с файлом
Во вкладке настройки можно изменить «Выбор языка», для распознавания текста файла. 

Цветовой режим
В меню «Цветовой режим» предлагается выбрать из цветного или черно-белого, причем во втором случае объем выдаваемого файла будет меньше и время на обработку уменьшится. 
На панели окна Изображение можно выбрать и отметить области распознавания, проверить результат работы и двух сопоставляемых (слева и справа) окнах. В правом – результате распознавания – при помощи встроенного текстового редактора правки можно вносить прямо в нем.
Программа выделяет 4 вида областей:
- Текст
- Картинка
- Фоновая картинка
- Таблица
После выполнения всех манипуляций необходимо запустить распознавание текста снова. Стоит заметить, что распознавать можно только отдельную область без обработки всех остальных страниц документа, что упрощает работу с большими файлами – просто выделите ее и нажмите кнопку «копировать». Необходимо знать, что рукописные тексты программа распознать не сможет. На примере ниже представлен неправильно выбранный документ, не подлежащий обработке.

Как пользоваться
Ознакомьтесь визуально с принципом работы данной программы:
Горячие клавиши
Помимо основных, отображаемых в пользовательском интерфейсе, клавиш, в FineReader существуют т.н. «горячие клавиши». Ниже приведен их неполный список.
Стандартные команды, знакомые нам по пакету MS Office:
- Ctrl+S – сохранение документа
- Ctrl+P – напечатать документ/текст
- Ctrl+Z – отмена предыдущей команды
- Ctrl+X, Ctrl+C, Ctrl+V – вырезать, скопировать, вставить текст/изображение
- И др.
Четыре в одном: обзор нового ABBYY FineReader 14
Новый FineReader 14 можно сравнить со швейцарским ножом — теперь под его личиной кроются сразу четыре продукта именитого разработчика, объединённых в одну программу с единым рабочим окружением. Помимо успевшей зарекомендовать себя с наилучшей стороны системы оптического распознавания текста Optical Character Recognition (OCR), которая обеспечивает конвертирование отсканированных изображений, фотографий, документов или PDF-файлов в редактируемые электронные форматы, в составе программы представлены редактор PDF, инструмент «Сравнение документов» для сравнения документов различных форматов, включая бумажные и электронные, а также средства автоматизации задач по конвертации документов Hot Folder. Вряд ли кто-то мог предполагать, что в почти четвертьвековой истории развития FineReader (первая версия продукта увидела свет в 1993 году) случится такой крутой поворот, однако в ABBYY убеждены в правильности выбранного курса и уверены, что подобного рода перемены сделают программу ещё более востребованной в пользовательской среде.

Новая концепция FineReader 14
Своё стремление уйти от устоявшихся традиций в компании объясняют современными тенденциями развития рынка электронного документооборота. Согласно проведённым ABBYY исследованиям, сотрудники различных организаций регулярно сталкиваются со следующими сценариями работы с документами: преобразование изображений и PDF-файлов в редактируемые форматы и внесение в них правок; сравнение документов разных форматов; создание, просмотр и редактирование PDF-файлов, а также извлечение из них данных. При этом типичный пользователь имеет дело с четырьмя и более сценариями и для решения каждой задачи использует разные программные продукты. В результате получается так, что вместо того, чтобы выполнять свою задачу, сотрудник компании занимается тем, что изучает эти инструменты и переключается между ними в процессе работы. Это очень неудобно и, по сути, является бесполезной тратой ресурсов, правильно распорядиться которыми должен новый FineReader 14.

ABBYY FineReader 14 предоставляет широкий спектр возможностей в одной программе
Не остались без изменений в обновлённом FineReader и фирменные технологии оптического распознавания текста ABBYY OCR и обработки структуры документа Adaptive Document Recognition Technology. Приложение определяет расположение текста, тип и размер шрифта, начертание и другие особенности форматирования, а также воссоздаёт структурные элементы — таблицы и диаграммы, колонки, заголовки, сноски, колонтитулы, номера страниц. В результате пользователь получает электронную копию документа, идентичную оригиналу. Распознанный текст можно сохранить как текстовый документ (DOCX, ODT, RTF), электронную таблицу (XLSX), презентацию (PPTX), файл HTML, электронную книгу (ePub и FB2), а также в форматах PDF и PDF/A.

Профессиональные инструменты для распознавания текста
FineReader 14 содержит набор инструментов, позволяющих визуально повысить качество сфотографированных или отсканированных документов и улучшить результат их распознавания. Программа автоматически применяет необходимые инструменты предварительной обработки для разных типов изображений. С помощью редактора изображений пользователь может вручную настроить яркость и контрастность фотографии, исправить перекос или трапециевидное искажение, убрать цифровой шум, обрезать лишние части изображения и многое другое.

С помощью встроенного в программу редактора пользователь может сравнить в одном окне оригинальный документ и распознанную копию. Расширенные функции по редактированию позволяют корректировать форматирование документа, вносить правки в текст, редактировать изображения, искать информацию, управлять страницами документа. Кроме того, имеется возможность вручную задавать области для распознавания и даже научить программу распознаванию специфических шрифтов.

В четырнадцатую версию FineReader были добавлены новые языки распознавания: математические символы (для распознавания однострочных математических формул) и английская транскрипция. Таким образом, теперь программа умеет оперировать документами на 192 мировых языках и любых их комбинациях.
Также при подготовке FineReader 14 к выпуску специалисты ABBYY увеличили скорость обработки и точность распознавания документов, доработали средства конвертирования PDF-файлов с текстовым слоем, улучшили работу с таблицами, графиками, диаграммами и документами на арабском языке. Множеству доработок подверглись другие компоненты программного комплекса. В частности, теперь FineReader позволяет создавать PDF-документы из файлов различных редактируемых форматов (DOCX, XLSX, RTF и др.) и объединять их в один PDF-документ.
Самый важный компонент нового FineReader – PDF-редактор, построенный на базе программы ABBYY PDF Transformer+. Приложение позволяет выполнять рецензирование и согласование PDF-документов, а также предлагает полный набор функций для их защиты от несанкционированного доступа и изменений. Кроме того, приложение интегрировано с Adobe PDF Library , что обеспечивает гарантированное открытие любых PDF -файлов и возможность внесения в них изменений без преобразования в редактируемый формат. С прицелом на корпоративный сегмент рынка в программе предусмотрены инструменты удаления конфиденциальной информации, добавления цифровой подписи и разграничения прав на печать и редактирование документов.

Внесение изменений в текст PDF-документов
FineReader 14 позволяет преобразовывать PDF в популярные форматы Microsoft Word, Excel, PowerPoint, HTML, OpenOffice (ODT) и другие. При этом исходная структура и форматирование документа сохраняются. Благодаря упомянутой выше поддержке ePub и FB2, пользователи могут создавать из PDF-документов любительские электронные книги для чтения на планшетах и других портативных устройствах. Отдельно стоит отметить возможность создания PDF из файлов изображений (JPEG, JPEG2000, JBIG2, PNG, BMP, GIF, TIFF) и поддержку потокового конвертирования документов.

Пригодится новый FineReader и тем, кто по долгу службы часто сталкивается с процессом согласования договоров или работает с документами, для которых характерна версионность. Возможности инструмента «Сравнение документов» позволяют сверять документы в различных форматах, быстро находить даже самые мелкие несоответствия в тексте и предотвращать тем самым подписание или публикацию некорректной версии документа. Автоматическое сравнение документов поможет существенно сэкономить время юристам, менеджерам по продажам, финансистам, логистам, а также всем офисным сотрудникам, которые сталкиваются со сравнением документов — договоров, актов, прайс-листов или других материалов.

Параллельный просмотр различий
Проводить сравнение документов можно как в текстовых, так и в графических (отсканированные документы или их фотографии, PDF без текстового слоя и т. п.) форматах. Для удобства работы с полученными результатами все обнаруженные несоответствия отображаются на отдельной панели, а также подсвечиваются по тексту в обоих документах. Предусмотрена возможность создания подробного отчёта о различиях и последующего его сохранения в виде таблицы в формате Word или PDF-документа с комментариями в местах изменений. Полученную таблицу можно использовать для вставки в отчёт о согласовании документов или для ведения переговоров с контрагентом. Несущественные различия перед формированием отчёта можно удалить.

Сохранение результатов сравнения
Для предприятий среднего и крупного бизнеса в составе FineReader 14 представлено приложение-планировщик ABBYY Hot Folder, с помощью которого можно автоматизировать однотипные или повторяющиеся задачи по обработке документов в сети организации. Возможности программы позволяют выполнять пакетное конвертирование файлов, преобразование документов по расписанию и обработку почтовых вложений. Для начала работы необходимо выбрать компьютер, который будет заниматься выполнением перечисленных операций, указать рабочую директорию на файловом сервере и настроить список задач.

Обработка документов по расписанию
Таковы основные отличительные особенности нового поколения FineReader, определённо заслуживающего внимания тех, кто часто занимается оцифровкой бумажных документов. Программа предназначена для запуска в среде Windows, совместима со всеми популярными моделями сканеров и многофункциональных устройств (МФУ) и поставляется разработчиком в трёх редакциях — Standard, Business и Enterprise. Они различаются набором включённых инструментов, формами поставки и условиями лицензирования.

Редакции и формы поставки ABBYY FineReader 14
И последний штрих. Как и в случае с предыдущими версиями FineReader, условия лицензионного договора допускают установку продукта на один стационарный и один мобильный компьютер при соблюдении двух требований: оба устройства должны принадлежать человеку, который приобрёл продукт, и одновременно может быть запущена только одна копия программы. Таким образом, приложение можно установить и на рабочий ноутбук, и на домашний ПК, не нарушая тем самым условий лицензионного соглашения с компанией ABBYY.
Получить дополнительную информацию об универсальном решении для работы с бумажными и PDF-документами FineReader 14, узнать о системных требованиях и условиях лицензирования можно на сайте abbyy.com/finereader.
См. также материалы по теме:
Как работать в ABBYY FineReader 12

Функциональное решение для сканирования документов ABBYY FineReader предоставляет возможность пользователю выбрать, в каком из популярных текстовых форматов сохранить файл. Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.
ABBYY FineReader 12, имеющаяся в наличии в SoftMagazin, обладает множеством полезных функций и значительно упрощает процесс распознавания текста и перевода его в формат PDF.
Как пользоваться программой ABBYY FineReader 12, описано в инструкции к программе, однако у пользователей могут остаться некоторые вопросы по ее настройке и запуску. В данном обзоре будут даны ответы о работе в ABBYY FineReader, как пользоваться этой программой, в частности последними ее версиями.

ABBYY FineReader: как работать
Для эффективной работы со сканируемыми документами нужно знать, для чего нужна ABBYY FineReader, как пользоваться основными функциями программы и правильно запускать ее. Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.
Особых различий в версии ABBYY FineReader 11, и как пользоваться 12 выпуском программы не наблюдается. Обе версии отличаются наличием хорошего функционала, поддержкой более 150 языков, в том числе и языков программирования и математических формул. Чтобы начать пользоваться программой, достаточно установить лицензионную версию на домашний или рабочий ПК и запустить ярлык ABBYY FineReader с рабочего стола или из меню Пуск.
Как установить ABBYY FineReader 11
Для установки программы на ПК нужно после приобретения лицензии, запустить из папки с программой или диска файл setup.exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке.


Как запустить ABBYY FineReader
 Запустить ярлык с рабочего стола компьютера
Запустить ярлык с рабочего стола компьютера
Выбрать в меню Пуск раздел Программы и запустить ABBYY FineReader
Если вы пользуетесь приложениями Microsoft Office, то достаточно нажать на инструментальной панели значок программы
Выберите в проводнике нужный документ и нажав правой кнопкой мыши, выберите в появившемся меню «Открыть с помощью ABBYY FineReader».
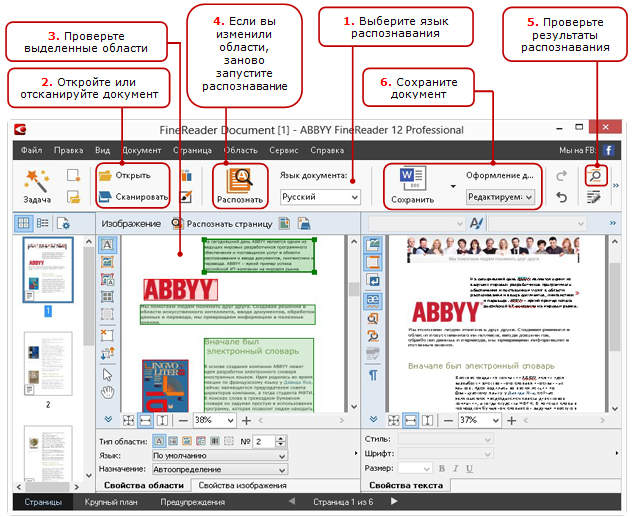
Как настроить ABBYY FineReader 12 Professional
Профессиональная версия ABBYY FineReader приобретается организациями для эффективной работы с программой в корпоративной сети и совместного редактирования файлов. Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.
Все автоматические функции могут использоваться в ручном режиме. Для комфортной работы перейдите на панели инструментов в «Сервис» и выберите пункт «Настройки», чтобы отрегулировать параметры. Можно самостоятельно задать настройки вида документа, режима сканирования, распознавания и сохранения файла.


ABBYY FineReader — как переводить
Для качественной конвертации документов в программе предусмотрены встроенные стандартные задачи, используя которые можно перевести документ в нужный формат, затратив минимум усилий. Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания.

