

Для чего нужно приложение синтезатор речи?
Что такое синтезаторы речи? Лучшие синтезаторы речи
Речевые синтезаторы, установленные на компьютеры или мобильные устройства, уже не кажутся такими необычными программами, как раньше. Благодаря современным технологиям обычный настольный ПК может воспроизводить человеческий голос.
Каким образом работают синтезаторы речи? Где они применяются? Какой самый лучший речевой синтезатор? Ответы на эти и другие вопросы изложены в данной статье.
Общее понятие
Синтезаторы речи являются специальными программами, состоящими из некоторого количества модулей, которые предоставляют возможность перевести набранные тексты в озвученные человеческим голосом предложения. Не стоит думать, что вся база слов и фраз записана реальными людьми в профессиональных студиях. Выполнить подобную задачу физически невозможно. Библиотеку с таким большим количеством фраз нельзя установить ни на один современный компьютер, не говоря уже о мобильных телефонах. Для этого разработчики создали технологию Text-to-Speech.

Сфера применения
Синтезаторы речи используются при изучении иностранных языков, прослушивании текстов на страницах книг, создании вокальных партий, выдаче поисковых запросов в форме озвученных фраз и т. п.
Какие разновидности программ существуют? В зависимости от сферы применения утилиты можно разделить на 2 вида: обычные, преобразующие набранный текст в речь, и специальные вокальные модули, используемые в музыкальных приложениях.
Для лучшего понимания рекомендуется рассмотреть оба класса, однако стоит акцентировать внимание на программах в их непосредственном значении.
Преимущества и недостатки
На данный момент компьютер синтезирует человеческую речь только приблизительно. В простейших программах можно наблюдать проблемы со звуком и правильной постановкой ударений в различных словах. Синтезаторы речи, установленные на мобильные устройства, расходуют много энергии. Нередко можно отметить несанкционированную загрузку дополнительных модулей.
К преимуществам следует отнести удобство восприятия. Многим пользователям гораздо проще усваивать звуковую информацию, нежели какую-либо другую.

Лучшие речевые синтезаторы с русскими голосами
Программа RHVoice была создана Ольгой Яковлевой. Стандартный вариант приложения включает 3 голоса. Настройки очень просты. Программу можно использовать и как самостоятельное приложение, совместимое с SAPI5, и как дополнительный экранный модуль.
Речевой синтезатор Acapela отличается от аналогов идеальным озвучиванием текста. Приложение поддерживает более 30 языков мира. В бесплатной версии доступен лишь 1 женский голос.
Программа Vocalizer часто применяется в call-центрах. Пользователь может настроить постановку ударения, громкость и скорость чтения. При необходимости загружаются дополнительные словари. В приложении есть 1 женский голос. Речевой движок автоматически встраивается в программы для чтения книг в электронном формате.
Утилита eSpeak поддерживает свыше 50 языков. Недостатком программы можно считать сохранение звуковых файлов лишь в формате WAV, который требует много места на жестком диске.
Приложение Festival является мощнейшей утилитой синтеза речи, поддерживающей даже финский язык и хинди.

Установка программы
Как использовать приложения такого типа? Для начала нужно установить программу. В компьютерных ОС применяется стандартный инсталлятор, в котором пользователю остается выбрать лишь поддерживаемый утилитой языковой модуль. Установщик для мобильных устройств можно скачать с официального сайта, Google Play, а также App Store. Инсталляция приложения происходит в автоматическом режиме.
Первый запуск программы
На данном этапе пользователю достаточно установить язык по умолчанию. Иногда требуется отметить качество звучания. Стандартный вариант подразумевает частоту дискретизации 4410 Гц, глубину 16 бит и битрейт 128 кбит/с. В мобильных ОС показатели могут быть ниже. В качестве основы используется определенный голос.
Фильтры и эквалайзеры помогают достичь необходимого звучания. Пользователю доступны три варианта перевода текста. Он может набрать на клавиатуре предложения, включить озвучивание уже имеющегося файла или установить в браузере расширение, которое преобразует содержимое на веб-страницах в речь. Достаточно отметить необходимый вариант действий, тембр голоса и язык, на котором будет произноситься текст. Для включения процесса воспроизведения требуется кликнуть по кнопке «Старт».

Работа со сложными программами
В музыкальных приложениях настройки гораздо сложнее. В речевом модуле программы FL Studio пользователь может выбрать несколько видов голосов, а также указать тональность и скорость воспроизведения. Постановка ударений перед слогами осуществляется с помощью символа «_». С помощью подобного речевого синтезатора можно создать лишь роботизированный голос.
Программа Vocaloid относится к приложениям профессионального типа. Помимо обычных параметров, пользователь может выбирать артикуляцию и глиссандо. В утилите есть база с вокалом профессионалов. При желании можно подгонять под ноты целые предложения. Одна только библиотека с вокалом занимает более 4 Гб в сжатом виде.
«Синтезатор речи Google»: что это за программа
В мае 2014 года компания предоставила пользователям возможность опробовать новый бесплатный продукт. Что такое «Синтезатор речи Google» на «Андроиде»? Это программа, озвучивающая текст на экране мобильного устройства или планшета. Теперь нет необходимости устанавливать сторонние утилиты, которые требуют наличия лицензии. «Синтезатор речи Google» используется при чтении электронных книг, прослушивании правильного произношения слов, запуске приложения TalkBack.
Новая версия программы «Синтезатор речи Google 3.1» получила функцию поддержки английского, итальянского, испанского, корейского, немецкого, нидерландского, польского, португальского, русского и французского языков. Где найти голосовые пакеты? Они загружаются из самого приложения.

Преимущества и недостатки продукта от Google
Особенностями русскоговорящего женского голоса является четкое, громкое звучание и плавная интонация. Скорость воспроизведения можно регулировать в настройках программы. Пользователи, использующие TalkBack и русскую языковую локализацию ОС Android, должны проявлять осторожность при переключении на речевой синтезатор, если ранее в приложении по умолчанию был установлен другой голос. Могут возникнуть проблемы, связанные с сохранением контроля над мобильным устройством на слух. Практически все голоса, кроме русского, неспособны обрабатывать предложения на кириллице.
Среди минусов можно отметить задержку реакции на чтение текстов, состоящих из фраз на разных языках. Русский голос отличается металлическими нотками тембра. Можно услышать дребезжащий звук на низких частотах. К преимуществам можно отнести стабильность работы приложения и приемлемое качество чтения англоязычных слов.
«Синтезатор речи Google»: как пользоваться программой
Для того чтобы утилита заработала как надо, требуется обновить ее до последней версии. Чтобы активировать процесс озвучивания текста, нужно открыть настройки. В разделе «язык и ввод» необходимо поставить флажок на пункте «синтез речи». Тут же следует отметить строку «система по умолчанию». Не стоит забывать о том, что голосовые пакеты в самой программе также нуждаются в обновлении.

Проблемы при работе с утилитой
При необходимости пользователь может отключить приложение. В самых простых утилитах кнопка остановки находится в самой программе. Деактивация расширения, установленного в браузере, производится путем отключения дополнения или полного удаления плагина. При работе с программой на мобильном телефоне также могут возникнуть проблемы. Дело в том, что синтезатор речи автоматически включает загрузку ненужных пользователю языковых модулей.
Данный процесс занимает много времени и существенно расходует трафик. Как отключить «Синтезатор речи Google» на мобильном устройстве и избавиться от этой проблемы? Для начала нужно открыть настройки приложения. Потом необходимо выбрать раздел «язык и голосовой ввод». Далее нужно отметить последнюю строку.
Выбрав голосовой поиск, следует кликнуть по крестику у пункта «распознавание речи офлайн». Затем рекомендуется удалить кэш приложений. Далее требуется перезагрузить мобильный телефон. Чтобы полностью отключить утилиту, необходимо открыть в настройках раздел «приложения», выбрать в списке синтезатор речи и кликнуть по кнопке «остановить».
Удаление программы
Бывает так, что пользователь вообще не использует «Синтезатор речи Google». Можно ли удалить утилиту с мобильного устройства? Для этого нужно открыть Google Play. Затем следует выбрать в перечне установленных программ синтезатор речи и кликнуть по кнопке «удалить».

Итоги
Обычным пользователям и людям с ограниченными возможностями подойдут приложения с простым интерфейсом. Это может быть как RHVoice, так и «Синтезатор речи Google». Русский голос озвучит отображаемый на экране текст. Большего рядовому пользователю не требуется.
Музыкантам рекомендуется отдавать предпочтение профессиональной программе Vocaloid. В приложении есть дополнительные голосовые библиотеки и множество различных опций. Программа позволит получить естественное звучание голоса. Ведь музыкантам так важно, чтобы компьютерный синтез не ощущался на слух.
Приложение Синтезатор речи Google: как пользоваться и как отключить?

Синтезатор речи от Google инсталлирован по умолчанию на смартфонах под управлением операционной системы Android. Многие слышали о нем, но не до конца понимают, что это, поэтому ищут способы , как его отключить. Однако ф актическ и н еудобства, которые доставляет вам озвучивание действий на вашем смартфоне , — это работа приложений, использующих синтезатор речи от Гугл, но не он сам, поэтому отключать его нет необходимости.
С другой стороны, пользователи не всегда используют полезные функции синтезатора , поэтому получается, что данная программа просто занимает место в смартфоне. Но полное ее удаление невозможно. Это системное приложение, которое нельзя удалить со смартфона. Все , что можно , — это остановить его работу и отключить его обновления, то есть сделать так, чтобы оно вам не мешало , но не более того.
Синтезатор речи от Google
Синтезатор речи от Гугл в вашем смартфоне — это очень безобидное приложение, которое самостоятельно не приносит неудобств, но активно используется другими приложениями.
Синтезатор речи от Google — это озвучивание текста в различных приложениях, поэтому он используется для:
озвучивания книг в приложении Google Play Книгах ;
озвучивания слов в Google Переводчике ;
предоставления специальных возможностей в приложениях для озвучивания текста на экране телефона;
использования в других приложениях телефона, где нужно озвучивать текст.
Как отключить синтезатор речи от Google на телефоне
Удалить полностью это приложение не получится, но отключить его вполне реально , и делается это , как и с любым другим приложением:
находите там «Все приложения»;
в этой вкладке находите «Синтезатор речи», нажимаете на эту вкладку;
вам будет доступно три действия: «Остановить», «Удалить обновления», «Отключить»;
выбира е те нужное действие.
Может так случит ь ся, что вы не хотите полностью останавливать работу этого приложения, но вас не устраивают его возможности и настройки. В этом случае вы можете установить любой другой синтезатор речи из Google Play Market и сменить в настройках встроенный синтезатор на ваш. Делается это по следующей инструкции:
найдите вкладку «Расширенные настройки» ;
найдите там вкладку «Специальные возможности» ;
отыщите там вкладку «Синтез речи» ;
найдите там вкладку «Альтернативное приложение» и активируйте сво ю программу, которую вы дополнительно установили.
Иногда так бывает, что проблемы вам приносит не синтезатор речи от Гугл, а другие приложения, которые его используют, например , TalkBack. Это приложение воспроизводит все, что происходит на экране вашего смартфона. Не всем пользователям это нравится, поэтому они предполагают, что виновен синтезатор речи, но фактически он тут не причем. Чтобы деактивировать TalkBack , необходимо:
открыть «Настройки» устройства ;
найти «Расширенные настройки» ;
отыскать «Специальные возможности» ;
найти там «TalkBack» и деактивировать это приложение.
Также иногда приносит неудобства другой функционал на Андроид-смартфоне — озвучивание при нажатии, котор ое также использует синтезатор речи от Google. Деактивировать этот функционал можно п о с ледующей инструкции:
откройте «Настройки» на устройстве ;
найдите пункт «Расширенные настройки» ;
отыщите пункт «Специальные возможности» ;
найдите пункт «Озвучивание при нажатии» и деактивируйте этот функционал.
Заключение
Синтезатор речи от Google — это встроенная функция в смартфонах на Android, которую нельзя удалить, но можно деактив и ровать. Основная масса пользователей вообще ей не пользуется, но некоторым она очень необходима. Если вы из тех, кто ей не пользуются, то вы уже знаете, как ее можно отключить.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Для чего нужно приложение синтезатор речи?

Краткое описание:
Синтезатор речи Google.
Описание:
Синтезатор речи Google озвучивает текст, который виден на экране устройства. Где это может пригодиться?
• В Google Play Книгах можно пользоваться функцией «Чтение вслух».
• В Google Переводчике можно слушать произношение слов.
• При использовании TalkBack и других специальных возможностей озвучиваются ваши действия.
• Также в Play Маркете есть много других приложений, в которых применяется синтез речи.
Функция доступна на следующих языках: английский (Австралия, Великобритания, Индия, США), бенгальский (Бангладеш), венгерский, датский, индонезийский, испанский (Испания, США), итальянский, кантонский (Гонконг), корейский, мандаринский (Китай, Тайвань), немецкий, нидерландский, норвежский, польский, португальский (Бразилия), русский, тайский, турецкий, финский, французский, хинди и японский.










Синтезатор речи Google читает только тогда, когда приложение позволяет сделать это.
Если браузер не поддерживает функцию запуска текста в речь, то и воспроизводиться ничего не будет.
Если хотите, чтобы браузер озвучивал выделенный текст, скачайте Яндекс браузер. Там есть такая функция
Как установить голосовой пакет вручную?
1. Скачать голосовой пакет (это zip-архив).
2. Извлечь содержимое архива в папку /data/data/com.google.android.tts/ . Для доступа к этой папке необходимы права root.
Как скачать голосовой пакет вручную?
В настоящее время адрес для скачивания языкового пакета (например, для русского языка) выглядит следующим образом https :// redirector.gvt1.com/edgedl/android/tts/v15/ru-ru-x-dfc-r
English (GB):
https :// redirector.gvt1.com/edgedl/android/tts/v15/en-gb-x-rjs-r 43 .zvoice
https :// redirector.gvt1.com/edgedl/android/tts/v15/en-gb-x-fis-r 43 .zvoice
English (US):
https :// redirector.gvt1.com/edgedl/android/tts/v15/en-us-x-sfg-r 45 .zvoice
Deutsch:
https :// redirector.gvt1.com/edgedl/android/tts/v15/de-de-x-nfh-r 41 .zvoice
Français:
https :// redirector.gvt1.com/edgedl/android/tts/v15/fr-fr-x-vlf-r 42 .zvoice
Español:
https :// redirector.gvt1.com/edgedl/android/tts/v15/es-es-x-ana-r 40 .zvoice
https :// redirector.gvt1.com/edgedl/android/tts/v15/es-us-x-sfb-r 42 .zvoice
Українська:
https :// redirector.gvt1.com/edgedl/android/tts/v15/uk-ua-x-hfd-r 9 .zvoice
Требуется Android: 5.0+
Русский интерфейс: Да
Разработчик: Google Inc.
E-mail разработчика: [email protected]
Домашняя страница: http://www.google.com
Google Play: https://play.google.com/store/apps/details?id=com.google.android.tts
Версия: 3.20.6.280280128 (All): Google Text-to-Speech (Синтезатор речи Google) (Пост iMiKED #91102147)
версия 3.19.17.270646921 (All): Google Text-to-Speech (Синтезатор речи Google) (Пост #89414433)
версия 3.19.16.270163878 (arm64): Google Text-to-Speech (Синтезатор речи Google) (Пост #89187738)
версия 3.18.14.261387622 (arm64): Google Text-to-Speech (Синтезатор речи Google) (Пост #87727923)
версия 3.18.13.260303084 (arm / arm64): Google Text-to-Speech (Синтезатор речи Google) (Пост #87584412)
версия 3.18.9.259456454 (arm / arm64): Google Text-to-Speech (Синтезатор речи Google) (Пост #87385738)
версия 3.17.4.244699203 (arm / arm64): Google Text-to-Speech (Синтезатор речи Google) (Пост #85515734)
Требуется Android: 4.0.3+ / 4.4+ (версии NEON)
версия 3.15.18.200023596: Google Text-to-Speech (Синтезатор речи Google) (Пост #74145208)
версия 3.15.17 (arm64): Google Text-to-Speech (Синтезатор речи Google) (Пост #73983262)
версия 3.14.12 (х86): Google Text-to-Speech (Синтезатор речи Google) (Пост #71271601)
версия 3.14.9 (arm NEON / х86): Google Text-to-Speech (Синтезатор речи Google) (Пост #68825031)
версия 3.14.7 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #67805151)
версия 3.14.6 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #67774008)
версия 3.13.3 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #66083564)
версия 3.13.2 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #65379722)
версия 3.12.9 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #63509245)
версия 3.12.8 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #63043156)
версия 3.12.2 (arm NEON)(8.0+): Google Text-to-Speech (Синтезатор речи Google) (Пост #61587537)
версия 3.11.12 (x86): Google Text-to-Speech (Синтезатор речи Google) (Пост #60176689)
версия 3.13.3 (х86): Google Text-to-Speech (Синтезатор речи Google) (Пост алекс12 #66130177)
версия 3.11.12 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #60176689)
версия 3.11.11 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #60078544)
версия 3.11.10 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #60011739)
версия 3.10.10 (x86): Google Text-to-Speech (Синтезатор речи Google) (Пост #53996581)
версия 3.10.10 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #53750543)
версия 3.10.9 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #53624469)
версия 3.10.9 (arm): Google Text-to-Speech (Синтезатор речи Google) (Пост onkolog #54031480)
версия 3.9.14 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #50474547)
версия 3.9.11 (x86):  com.google.android.tts_3.9.11_x86.apk ( 13,56 МБ )
com.google.android.tts_3.9.11_x86.apk ( 13,56 МБ )
версия 3.9.11 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #49869119)
версия 3.9.11 (arm): Google Text-to-Speech (Синтезатор речи Google) (Пост #49947229)
версия 3.9.6 mod: Google Text-to-Speech (Синтезатор речи Google) (Пост #49816808)
версия 3.9.6 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #49779491)
версия 3.8.17 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #49830320)
версия 3.8.16 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #47954663)
версия 3.8.16 (arm): Google Text-to-Speech (Синтезатор речи Google) (Пост #48232188)
версия 3.8.16 (x86): com.google.android.tts_3.8.16_x86.apk ( 13,39 МБ )
версия 3.8.14 (arm NEON): Google Text-to-Speech (Синтезатор речи Google) (Пост #47207737)
версия 3.8.14 (arm + x86): Google Text-to-Speech (Синтезатор речи Google) (Пост #47211873)
версия 3.8.13 (arm): Google Text-to-Speech (Синтезатор речи Google) (Пост #47007743)
версия 3.8.11 (arm): Google Text-to-Speech (Синтезатор речи Google) (Пост #46813869)
версия 3.7.12.2235583.arm.arm_neon: Google Text-to-Speech (Синтезатор речи Google) (Пост #42962600)
версии 3.5.6 — 3.7.12 ( Mod ): Google Text-to-Speech (Синтезатор речи Google) (Пост #41685110)
версия 3.7.12.2235583.arm: Google Text-to-Speech (Синтезатор речи Google) (Пост #39130185)
версия 3.7.12.2235583.x86: Google Text-to-Speech (Синтезатор речи Google) (Пост #43152607)
версия 3.5.6.2080558.arm.neon: Google Text-to-Speech (Синтезатор речи Google) (Пост #41509182)
версия 3.5.6.2080558.arm: Google Text-to-Speech (Синтезатор речи Google) (Пост #39130185)
версия 3.5.5.2050975.arm: Google Text-to-Speech (Синтезатор речи Google) (Пост #39130185)
версия 3.4.6.1819666.arm ( Mod ): Google Text-to-Speech (Синтезатор речи Google) (Пост #39607460)
версия 3.4.6.1819666.x86: Google Text-to-Speech (Синтезатор речи Google) (Пост #41207944)
версия 3.4.5.1772910.x86: Google Text-to-Speech (Синтезатор речи Google) (Пост #38792138)
версия 3.4.5.1772910: Google Text-to-Speech (Синтезатор речи Google) (Пост #38792138)
версия 3.3.13.1635260.arm: Google Text-to-Speech (Синтезатор речи Google) (Пост #36434603)
версия 3.3.12.1616444: Google Text-to-Speech (Синтезатор речи Google) (Пост #36222401)
версия 3.2.12.1369973: Google Text-to-Speech (Синтезатор речи Google) (Пост #34162389)
версия 3.1.3.1162895: com.google.android.tts_3.1.3.1162895.apk ( 13,04 МБ )
Синтезатор речи на компьютер
Синтезатор речи от Гугл — это полезное приложение, основная функция которого — чтение текста с экрана смартфона. Программа была разработана корпорацией Google и хорошо работает с другими продуктами Google, такими как Google Play Книги, Google Translate и многие другие. Скачать Синтезатор речи на ПК можно с нашего портала.


О приложении
Синтезаторы речи — это специальные программы, содержащие определенное количество модулей. Именно с их помощью вы можете читать набираемый текст. Многие пользователи считают, что озвученный программой голос был записан реальными людьми в студии. Но это мнение ошибочно.
Использование готовых аудиозаписей невозможно. Включить в программу достаточное количество готовых фраз и словосочетаний нереально. Такое приложение нельзя было установить ни на один компьютер, не говоря уже о мобильных гаджетах.
Было разработано много синтезаторов речи, но распространилась версия корпорации Google. Их приложение позволяет воспроизводить текст в разных приложениях. Многие пользователи считают, что это лучший синтезатор речи.
Применяется в следующих случаях:
- дубляж книг в приложении Google Play;
- перевод иностранных слов в официальном переводчике Google;
- голос поверх текста, отображаемого на экране (эта функция будет полезна в TalkBack и других сервисах).

Возможности приложения на ПК
Чтобы использовать старую версию синтезатора речи, вам необходимо сделать следующее:
- зайдите в раздел «Настройки» на телефоне и выберите «Язык и ввод»;
- затем нажмите «Преобразование текста в речь»;
- последний шаг, функция преобразования текста в речь Google.
Вы можете загрузить Синтезатор речи на компьютер в этом разделе сайта. Это займет всего лишь несколько минут. Мы предлагаем широкий выбор бесплатного программного обеспечения.
Плюсы и минусы
Озвученный женский голос в программе. Это громко и ясно. Создатели позаботились и о плавной интонации. Пользователь может регулировать скорость чтения и управлять другими настройками. Простое и понятное меню также можно рассматривать как положительные черты приложения.
У этой программы тоже есть недостатки. Пользователи сообщают о задержках при чтении на нескольких языках. Есть металлические нотки на русском языке. Дребезжание слышно на низких частотах.
Как установить Синтезатор речи на ПК
Чтобы скачать мобильную игру на свой компьютер, вам потребуется скачать дополнительное программное обеспечение. На этом веб-сайте вы можете скачать бесплатную программу, которая будет эмулировать среду Android и позволит игрокам загружать на ПК все игры и приложения из Google Play для мобильных телефонов. Пока что эмулятор BlueStacks 5 считается лучшим программным обеспечением со схожими функциями.
Итак, чтобы установить приложение Синтезатор речи на ноутбук, нужно сделать следующее:
-
После загрузки программного обеспечения вам необходимо начать процесс установки. Вы должны выбрать место, где будут установлены все необходимые программные компоненты, и принять лицензионное соглашение. После завершения загрузки вы можете запустить эмулятор, дважды щелкнув ярлык на рабочем столе.




Похожие приложения
- Google Translate — самый популярный онлайн-переводчик, и его функциональность увеличивается с каждым новым обновлением. Функциональность приложения позволяет переводить текст с помощью камеры устройства, что значительно сокращает временные промежутки в языковом барьере и делает путешествия по миру более имеется в наличии. Переводы на 103 языка доступны пользователям со всего мира, что упрощает общение с иностранцами и минимизирует языковые барьеры.
- Google Диск для Android — это облачный сервис, который служит универсальным хранилищем самой ценной и необходимой информации. Приложение позволяет загружать в облачный сервис разного рода файлы, после чего они будут доступны вам в любой точке мира, с любого устройства, будь то персональный компьютер, планшет или смартфон.
Видео-обзор
Скачать Синтезатор речи на ПК
Ни для кого не секрет: зрительное восприятие происходит намного быстрее, чем на слух. Но современный уровень жизни не всегда позволяет быстро воспринимать данные с экрана гаджетов. Было изобретено огромное количество голосовых плагинов, но их качество продолжает оставаться низким. Если вам нужен действительно качественный инструмент, синтезатор речи Google уже создан для вас. Приложение избавит ваши глаза от стресса работы с экраном, не теряя при этом данные. Программа полностью взаимодействует со всеми сервисами Google. Скачать Синтезатор речи на ПК через эмулятор BlueStacks 5 можно по ссылке ниже.
Обзор технологий синтеза речи
Всем привет! Меня зовут Влад и я работаю data scientist-ом в команде речевых технологий Тинькофф, которые используются в нашем голосовом помощнике Олеге.
В этой статье я бы хотел сделать небольшой обзор технологий синтеза речи, использующихся в индустрии, и поделиться опытом нашей команды построения собственного движка синтеза.

Синтез речи
Синтез речи — это создание звука на основе текста. Эту задачу сегодня решают двумя подходами:
- Unit selection [1], или конкатенативный подход. Он основан на склейке фрагментов записанного аудио. С конца 90-х долгое время он считался де-факто стандартом для разработки движков синтеза речи. Например, голос, звучащий по методу unit selection, можно было встретить в Siri [2].
- Параметрический синтез речи [3], суть которого состоит в построении вероятностной модели, предсказывающей акустические свойства аудиосигнала для данного текста.
Речь моделей unit selection имеет высокое качество, низкую вариативность и требует большого объема данных для обучения. В то же время для тренировки параметрических моделей необходимо гораздо меньшее количество данных, они генерируют более разнообразные интонации, но до недавнего времени страдали от общего достаточно низкого качества звука по сравнению с подходом unit selection.
Однако с развитием технологий глубокого обучения модели параметрического синтеза достигли существенного прироста по всем метрикам качества и способны создавать речь, практически неотличимую от человеческой.
Метрики качества
Прежде чем говорить о том, какие модели синтеза речи лучше, нужно определить метрики качества, по которым будет проводиться сравнение алгоритмов.
Поскольку один и тот же текст можно прочитать бесконечным количеством способов, априори правильного способа для произношения конкретной фразы не существует. Поэтому зачастую метрики качества синтеза речи субъективны и зависят от восприятия слушающего.
Стандартная метрика — это MOS (mean opinion score), усредненная оценка естественности речи, выданная асессорами для синтезированных аудио по шкале от 1 до 5. Единица означает совсем неправдоподобное звучание, а пятерка — речь, неотличимую от человеческой. Реальные записи людей обычно получают значения примерно 4,5, и значение больше 4 считается достаточно высоким.
Как работает синтез речи
Первый шаг к построению любой системы синтеза речи — сбор данных для обучения. Обычно это аудиозаписи высокого качества, на которых диктор читает специально подобранные фразы. Примерный размер датасета, необходимый для обучения моделей unit selection, составляет 10—20 часов чистой речи [2], в то время как для нейросетевых параметрических методов верхняя оценка равна примерно 25 часам [4, 5].
Обсудим обе технологии синтеза.
Unit selection
Обычно записанная речь диктора не может покрыть всех возможных случаев, в которых будет использоваться синтез. Поэтому суть метода состоит в разбиении всей аудиобазы на небольшие фрагменты, называющиеся юнитами, которые затем склеиваются друг с другом с использованием минимальной постобработки. В качестве юнитов обычно выступают минимальные акустические единицы языка, такие как полуфоны или дифоны [2].
Весь процесс генерации состоит из двух этапов: NLP frontend, отвечающий за извлечение лингвистического представления текста, и backend, который вычисляет функцию штрафа юнитов для заданных лингвистических признаков. В NLP frontend входят:
- Задача нормализации текста — перевод всех небуквенных символов (цифр, знаков процентов, валют и так далее) в их словесное представление. Например, “5 %” должно быть переведено в “пять процентов”.
- Извлечение лингвистических признаков из нормализованного текста: фонемное представление, ударения, части речи и так далее.
Обычно NLP frontend реализован с помощью вручную прописанных правил для конкретного языка, однако в последнее время происходит все больший уклон в сторону использования моделей машинного обучения [7].
Штраф, оцениваемый backend-подсистемой, — это сумма target cost, или соответствия акустического представления юнита для конкретной фонемы, и concatenation cost, то есть уместности соединения двух соседних юнитов. Для оценки штраф функций можно использовать правила или уже обученную акустическую модель параметрического синтеза [2]. Выбор наиболее оптимальной последовательности юнитов с точки зрения выше определенных штрафов происходит с помощью алгоритма Витерби [1].
Примерные значения MOS моделей unit selection для английского языка: 3,7—4,1 [2, 4, 5].
Достоинства подхода unit selection:
- Естественность звучания.
- Высокая скорость генерации.
- Небольшой размер моделей — это позволяет использовать синтез прямо на мобильном устройстве.
- Синтезируемая речь монотонна, не содержит эмоций.
- Характерные артефакты склейки.
- Требует достаточно большой тренировочной базы аудиоданных для покрытия всевозможных контекстов.
- В принципе не может генерировать звук, не встречающийся в обучающей выборке.
Параметрический синтез речи
В основе параметрического подхода лежит идея о построении вероятностной модели, оценивающей распределение акустических признаков заданного текста.
Процесс генерации речи в параметрическом синтезе можно разделить на четыре этапа:
- NLP frontend — такая же стадия предобработки данных, как и в подходе unit selection, результат которой — большое количество контекстно-зависимых лингвистических признаков.
- Duration model, предсказывающая длительность фонем.
- Акустическая модель, восстанавливающая распределение акустических признаков по лингвистическим. В акустические признаки входят значения фундаментальной частоты, спектральное представление сигнала и так далее.
- Вокодер, переводящий акустические признаки в звуковую волну.
Для обучения duration и акустической моделей можно использовать скрытые марковские модели [3], глубокие нейронные сети или их рекуррентные разновидности [6]. Традиционный вокодер — это алгоритм, основанный на source-filter модели [3], которая предполагает, что речь — это результат применения линейного фильтра шума к первоначальному сигналу.
Общее качество речи классических параметрических методов оказывается достаточно низким из-за большого количества независимых предположений об устройстве процесса генерации звука.
Однако с приходом технологий глубокого обучения стало возможным обучать end-to-end модели, которые напрямую предсказывают акустические признаки по буквам. Например, нейронные сети Tacotron [4] и Tacotron 2 [5] принимают на вход последовательность букв и возвращают мел-спектрограмму с помощью алгоритма seq2seq [8]. Таким образом шаги 1—3 классического подхода заменяются одной нейросетью. На схеме ниже показана архитектура сети Tacotron 2, достигающей достаточно высокого качества звука.
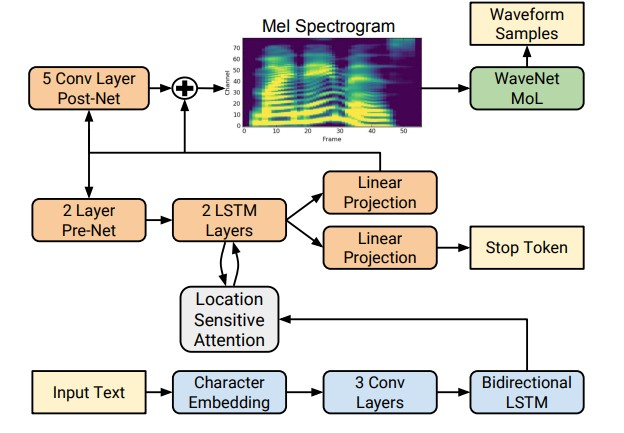
Другим фактором существенного прироста в качестве синтезируемой речи стало применение нейросетевых вокодеров вместо алгоритмов цифровой обработки сигналов.
Первым таким вокодером была нейронная сеть WaveNet [9], которая последовательно, шаг за шагом, предсказывала значения амплитуды звуковой волны.
Благодаря использованию большого количества сверточных слоев с пропусками для захвата большего контекста и skip connection в архитектуре сети удалось достичь примерно 10%-го улучшения MOS по сравнению с моделями unit selection. На схеме ниже представлена архитектура сети WaveNet.

Главный недостаток WaveNet — низкая скорость работы, связанная с последовательной схемой сэмплирования сигнала. Эту проблему можно решить либо с помощью инженерной оптимизации для конкретной архитектуры железа, либо заменой схемы сэмплирования на более быструю.
Оба подхода были успешно реализованы в индустрии. Первый — в Tinkoff.ru, а в рамках второго подхода компания Google представила сеть Parallel WaveNet [10] в 2017 году, наработки которой используются в Google Assistant.
Примерные значения MOS для нейросетевых методов: 4,4—4,5 [5, 11], то есть синтезируемая речь практически не отличается от человеческой.
Достоинства параметрического синтеза:
- Естественное и плавное звучание при использовании end-to-end подхода.
- Большее разнообразие в интонациях.
- Использование меньшего объема данных по сравнению с моделями unit selection.
- Низкая скорость работы по сравнению с unit selection.
- Большая вычислительная сложность.
Как работает синтез речи в Tinkoff
Как следует из обзора, методы параметрического синтеза речи, основанные на нейросетях, на текущий момент существенно превосходят по качеству подход unit selection и гораздо проще для разработки. Поэтому для построения собственного движка синтеза мы использовали именно их.
Для обучения моделей было использовано около 25 часов чистой речи профессионального диктора. Тексты для чтения были специально подобраны так, чтобы наиболее полно покрыть фонетику разговорной речи. Кроме того, чтобы добавить синтезу большее разнообразие в интонации, мы попросили диктора читать тексты с выражением, зависящим от контекста.
Архитектура нашего решения концептуально выглядит так:
- NLP frontend, в который входит нейросетевая текстовая нормализация и модель по расстановке пауз и ударений.
- Tacotron 2, принимающий на вход буквы.
- Авторегрессионный WaveNet, работающий в real time на CPU.
Благодаря такой архитектуре наш движок генерирует выразительную речь высокого качества в режиме реального времени, не требует построения фонемного словаря и дает возможность управлять ударениями в отдельных словах. Примеры синтезированных аудио можно прослушать, перейдя по ссылке.
Ссылки:
[1] A. J. Hunt, A. W. Black. Unit selection in a concatenative speech synthesis system using a large speech database, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio, R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System, Interspeech, 2017.
[3] H. Zen, K. Tokuda, A. W. Black. Statistical parametric speech synthesis, Speech Communication, Vol. 51, no. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous. Tacotron: Towards End-to-End Speech Synthesis.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Statistical parametric speech synthesis using deep neural networks.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman, Brian Roark. Neural Models of Text Normalization for Speech Applications.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Networks.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Fast High-Fidelity Speech Synthesis.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech.
[12] Dario Rethage, Jordi Pons, Xavier Serra. A Wavenet for Speech Denoising.
Как разработать собственный синтез речи и составить конкуренцию Google и «Яндексу»
История о том, как разработать технологию для синтеза речи с бюджетом 3 миллиона рублей (с примерами и этапами).
Всем привет. Мы уже писали здесь статью об использовании голосового бота в колл-центре транспортной компании и сейчас мы пошли дальше. Мы решили создать собственный синтез речи, способный конкурировать с такими гигантами как Google, Yandex, Amazon и относительно новыми игроками на этом рынке как Тинькофф, АБК и Vera Voice.
Мы команда из 35 человек децентрализованно работающих по разным городам и странам. В 2016 году мы начали работать под брендом Twin. Тогда мы начинали с простых голосовых ботов. Сейчас это уже более сложные модели со сложными сценариями, машинным обучением и гибкой маршрутизацией в телефонии. Не буду подробно останавливаться на этом, гораздо подробнее и интереснее это описано на нашем сайте.
Сейчас я немного опишу вводную информацию по синтезу речи в 2020 году: что есть на рынке, как это используется, для чего, сколько стоит и какие проблемы возникают. Кому эта информация не интересна, примеры синтеза начинаются после заголовка “Первые результаты”. Приятного прочтения!
Сейчас синтез речи используется в основном в различных умных колонках, голосовых помощниках и в меньшей степени для уведомлений и общения с клиентом. Мы подробнее остановимся именно на синтезе для телефонии.
Почему в звонках используется синтез речи? При общении с голосовым ботом или при уведомлении от голосового бота часто озвучиваются различные переменные, масштаб вариаций которых может достигать несколько миллионов значений. Например, уведомление о доставке груза, где используются ФИО, даты, город, улица, числа. Одних только имён может быть около 60 тысяч и озвучить всё диктором будет трудоемкой задачей и помимо этого добавит зависимости от одного диктора. Таким образом, для гибкости и оперативности при разработке голосовых ботов синтез подходит наилучшим образом нежели предзаписанная речь.
Плюсы: позволяет синтезировать речь на основе любого текста в реальном времени.
Минусы: при большом объёме синтезированной речи очень сложно придать ей необходимую и естественную эмоциональную окраску.
Плюсы: мы можем придать любой эмоциональный окрас, скорость и тембр речи, объяснив диктору, что мы в итоге хотим услышать.
Минусы: очень сложно и трудозатрано предзаписать большой объём переменной информации и учесть все возможные доработки сценариев бота.
При совмещении плюсов и минусов предзаписи и индивидуального синтеза речи мы получим идеальное сочетание.
Вот пример стороннего синтеза при звонке
К 2020 году на рынке сформировались несколько глобальных игроков и несколько локальных со своими плюсами и минусами.
Глобальные: Google, Amazon
Локальные: Yandex, Tinkoff, АБК, Vera Voice
В конце 2019 года мы задумались о реализации собственного синтеза. Да, в краткосрочной перспективе это получается невыгодно, но в перспективе от 2-х лет эта история очень интересна для нас. Дополнительным толчком также стали запросы от клиентов с потребностью синтеза речи определенного диктора. То есть у клиентов возникла потребность создать гибридный вариант голоса при звонках, когда часть диалога происходит с использованием предзаписанных реплик, а переменные синтезируются на основе голоса их диктора.
Итак, на первый взгляд эта идея кажется обязательной для компании, работающей в сфере голосовых ботов, но цена реализации неизвестна. В процессе исследования мы поняли, что реализовать синтез мы можем, но его качество в большей степени зависит от собранных данных исходного голоса и его доработок, потому что основные и ключевые технологии создания синтеза открыты и доступны.
Для сравнения, в 2019 Tinkoff только на свой суперкомпьютер «Колмогоров» потратили около 1 млн. долларов без расходов на разработку программного обеспечения. О стоимости разработки ПО можно только гадать, информацию в открытых источниках мне не удалось найти.
Нам нужен был качественный синтез со стоимостью разработки не более 3 млн. рублей и возможностью активно масштабировать эту модель в течении 1 года, а дальше пополнять уже новый бюджет за счет новых клиентов. Ключевыми критериями были:
-
Стоимость разработки и сопровождения ПО
Приемлемое качество для использования в телефонии
Возможность создавать синтез на основе 1 часа речи диктора
Практически любой синтез речи на базе нейронных сетей состоит из 3 основных модулей:
- Нормализация текста.
- Синтез спектрограммы из текста.
- Синтез аудиоданных из спектрограммы (вокодер).
Для своей реализации синтеза речи мы решили дорабатывать Tacotron 2 и WaveGlow под свои нужды.
Первые результаты.
Во время первых попыток обучения Tacotron 2 мы разбирались с архитектурой нейронной сети: как с ней работать, как её обучать и использовать. Первые результаты нас не устроили, но потом удалось добиться устойчивого синтеза с минимальными проблемами. За исключением того, что спектрограмма переводилась в аудиоданные с помощью алгоритма Гриффин-Лима, который даёт крайне сильный «металлический отблеск» в полученной синтезированной речи.
Для наглядности я прикреплю к каждому из этапов примеры синтеза и оригинальной записи диктора.
Второй этап
Звучание синтеза было явно на уровне крайне сырого прототипа и вряд ли бы устроило какого-либо клиента. На начальном этапе мы сомневались в привлекательности будущего результата, поэтому решили пойти дальше и разбираться с более качественными подходами для перевода спектрограммы в аудиоданные. Теперь синтез речи стал полностью нейросетевым и звучит намного приятнее, естественнее. Так же были вручную проверены и очищены данные для обучения, что немного упростило и ускорило процесс обучения.
Третий этап
Добавили небольшие изменения в архитектуре нейронной сети, пересмотрели подходы к обучению моделей, подготовили аудиозаписи для обучения, добавили перевод слов в набор фонем. Благодаря этому получилось обучить модель всего на 3-х часах аудиозаписей, вместо 10-20 часов ранее.
Четвертый этап
Русский язык
На этом этапе мы провели более масштабную работу. Добавили ещё несколько изменений в архитектуре нейронной сети, оптимизировали процесс подготовки аудиозаписей и обучения, добавили расстановку ударений и обработку ударных и безударных фонем. Существенно доработали процесс обучения моделей, благодаря которым получилось обучить модель всего на 1-м часе аудиозаписей без особой потери в качестве и стабильности синтеза.
Английский язык
Параллельно мы записали 1 час с англоговорящим диктором и перенесли полученный результата с русского языка на английский. Архитектура нейронной сети и процессы обучения такие же, как на русском языке, но пока что без перевода слов в набор фонем и поддержки ударений. Модель для английского языка обучена так же на 1-ом часе аудиозаписей.