

Как установить голосовые данные для синтеза речи?
Как настроить синтезатор речи Google на Android

В то время как Google фокусируется на Помощнике, владельцы Android не должны забывать о функции синтеза речи (TTS). Она преобразует текст из Ваших приложений для Android, но Вам может потребоваться изменить его, чтобы речь звучала так, как Вы этого хотите.
Изменение синтеза речи легко сделать из меню настроек специальных возможностей Android. Вы можете изменить скорость и тон выбранного Вами голоса, а также используемый голосовой движок.
Синтезатор речи Google — это голосовой движок по умолчанию, который предварительно установлен на большинстве устройств Android. Если на Вашем Android-устройстве он не установлен, Вы можете загрузить приложение Синтезатор речи Google из Google Play Store.










Изменение скорости речи и высоты тона
Android будет использовать настройки по умолчанию для Синтезатора речи Google, но Вам может потребоваться изменить скорость и высоту голоса, чтобы Вам было легче его понять.
Изменение скорости речи и высоты тона TTS требует, чтобы Вы попали в меню настроек специальных возможностей Google. Шаги для этого могут незначительно отличаться, в зависимости от Вашей версии Android и производителя Вашего устройства. В данной статье используется устройство Honor 8 lite, работающее на Android 8.0.
Чтобы открыть меню специальных возможностей Android, перейдите в меню «Настройки» Android. Это можно сделать, проведя пальцем вниз по экрану для доступа к панели уведомлений и нажав значок шестеренки в правом верхнем углу, или запустив приложение «Настройки» в своем списке приложений.

В меню «Настройки» нажмите «Управление», а оттуда «Специальные возможности».


Выберите «Синтез речи».

Отсюда Вы сможете изменить настройки преобразования текста в речь.
Изменение скорости речи
Скорость речи — это скорость, с которой будет говорить синтезатор речи. Если Ваш TTS движок слишком быстрый (или слишком медленный), речь может звучать искаженно или плохо для понимания.
Если Вы выполнили вышеуказанные действия, Вы должны увидеть слайдер под заголовком «Скорость речи» в меню «Синтез речи». Проведите пальцем вправо или влево, чтобы повысить или понизить скорость.

Нажмите кнопку «Прослушать пример», чтобы проверить новый уровень речи.

Изменение высоты тона
Если Вы чувствуете, что тон преобразованного текста в речь слишком высок (или низок), Вы можете изменить это, следуя тому же процессу, что и при изменении скорости речи.
Как и выше, в меню настроек «Синтез речи» отрегулируйте ползунок «Тон» в соответствии с желаемой высотой тона.

Когда Вы будете готовы, нажмите «Прослушать пример», чтобы попробовать новый вариант.
Продолжайте этот процесс, пока Вы не будете довольны настройками скорости речи и высоты тона, или нажмите «Сбросить скорость речи» и/или «Сбросить настройки тона», чтобы вернуться к настройкам TTS по умолчанию.

Выбор голоса синтезатора речи
Вы можете не только изменить тон и скорость своего речевого движка TTS, но и изменить голос. Некоторые языковые пакеты, включенные в стандартный движок Синтезатор речи Google, имеют разные голоса, которые звучат как мужской, так и женский.
Если Вы используете Синтезатор речи Google, нажмите кнопку «i» рядом названием.

В меню «Настройки» нажмите «Установка голосовых данных».

Нажмите на выбранный Вами язык.

Вы увидите различные голоса, перечисленные и пронумерованные, начиная с «Голоса I». Нажмите на каждый, чтобы услышать, как он звучит. Вы должны убедиться, что на Вашем устройстве включен звук.

Выберите голос, который Вас устраивает в качестве Вашего окончательного выбора.

Ваш выбор будет автоматически сохранен, хотя, если Вы выбрали другой язык по умолчанию для Вашего устройства, Вам также придется изменить его.
Переключение языков
Если Вам нужно переключить язык, Вы можете легко сделать это из меню настроек Синтеза речи. Возможно, Вы захотите сделать это, если Вы выбрали язык в Вашем движке TTS, отличный от языка Вашей системы по умолчанию.
Вы должны увидеть опцию «Язык». Нажмите, чтобы открыть меню.

Выберите свой язык из списка, нажав на него.

Сторонние движки синтезатора речи
Если Синтезатор речи Google Вам не подходит, Вы можете установить альтернативные варианты.
Их можно установить из Google Play Store или установить вручную. Примеры движков TTS, которые Вы можете установить, включают Acapela и eSpeak TTS, хотя доступны и другие.
Как разработать собственный синтез речи и составить конкуренцию Google и «Яндексу»
История о том, как разработать технологию для синтеза речи с бюджетом 3 миллиона рублей (с примерами и этапами).
Всем привет. Мы уже писали здесь статью об использовании голосового бота в колл-центре транспортной компании и сейчас мы пошли дальше. Мы решили создать собственный синтез речи, способный конкурировать с такими гигантами как Google, Yandex, Amazon и относительно новыми игроками на этом рынке как Тинькофф, АБК и Vera Voice.
Мы команда из 35 человек децентрализованно работающих по разным городам и странам. В 2016 году мы начали работать под брендом Twin. Тогда мы начинали с простых голосовых ботов. Сейчас это уже более сложные модели со сложными сценариями, машинным обучением и гибкой маршрутизацией в телефонии. Не буду подробно останавливаться на этом, гораздо подробнее и интереснее это описано на нашем сайте.
Сейчас я немного опишу вводную информацию по синтезу речи в 2020 году: что есть на рынке, как это используется, для чего, сколько стоит и какие проблемы возникают. Кому эта информация не интересна, примеры синтеза начинаются после заголовка “Первые результаты”. Приятного прочтения!
Сейчас синтез речи используется в основном в различных умных колонках, голосовых помощниках и в меньшей степени для уведомлений и общения с клиентом. Мы подробнее остановимся именно на синтезе для телефонии.
Почему в звонках используется синтез речи? При общении с голосовым ботом или при уведомлении от голосового бота часто озвучиваются различные переменные, масштаб вариаций которых может достигать несколько миллионов значений. Например, уведомление о доставке груза, где используются ФИО, даты, город, улица, числа. Одних только имён может быть около 60 тысяч и озвучить всё диктором будет трудоемкой задачей и помимо этого добавит зависимости от одного диктора. Таким образом, для гибкости и оперативности при разработке голосовых ботов синтез подходит наилучшим образом нежели предзаписанная речь.
Плюсы: позволяет синтезировать речь на основе любого текста в реальном времени.
Минусы: при большом объёме синтезированной речи очень сложно придать ей необходимую и естественную эмоциональную окраску.
Плюсы: мы можем придать любой эмоциональный окрас, скорость и тембр речи, объяснив диктору, что мы в итоге хотим услышать.
Минусы: очень сложно и трудозатрано предзаписать большой объём переменной информации и учесть все возможные доработки сценариев бота.
При совмещении плюсов и минусов предзаписи и индивидуального синтеза речи мы получим идеальное сочетание.
Вот пример стороннего синтеза при звонке
К 2020 году на рынке сформировались несколько глобальных игроков и несколько локальных со своими плюсами и минусами.
Глобальные: Google, Amazon
Локальные: Yandex, Tinkoff, АБК, Vera Voice
В конце 2019 года мы задумались о реализации собственного синтеза. Да, в краткосрочной перспективе это получается невыгодно, но в перспективе от 2-х лет эта история очень интересна для нас. Дополнительным толчком также стали запросы от клиентов с потребностью синтеза речи определенного диктора. То есть у клиентов возникла потребность создать гибридный вариант голоса при звонках, когда часть диалога происходит с использованием предзаписанных реплик, а переменные синтезируются на основе голоса их диктора.
Итак, на первый взгляд эта идея кажется обязательной для компании, работающей в сфере голосовых ботов, но цена реализации неизвестна. В процессе исследования мы поняли, что реализовать синтез мы можем, но его качество в большей степени зависит от собранных данных исходного голоса и его доработок, потому что основные и ключевые технологии создания синтеза открыты и доступны.
Для сравнения, в 2019 Tinkoff только на свой суперкомпьютер «Колмогоров» потратили около 1 млн. долларов без расходов на разработку программного обеспечения. О стоимости разработки ПО можно только гадать, информацию в открытых источниках мне не удалось найти.
Нам нужен был качественный синтез со стоимостью разработки не более 3 млн. рублей и возможностью активно масштабировать эту модель в течении 1 года, а дальше пополнять уже новый бюджет за счет новых клиентов. Ключевыми критериями были:
-
Стоимость разработки и сопровождения ПО
Приемлемое качество для использования в телефонии
Возможность создавать синтез на основе 1 часа речи диктора
Практически любой синтез речи на базе нейронных сетей состоит из 3 основных модулей:
- Нормализация текста.
- Синтез спектрограммы из текста.
- Синтез аудиоданных из спектрограммы (вокодер).
Для своей реализации синтеза речи мы решили дорабатывать Tacotron 2 и WaveGlow под свои нужды.
Первые результаты.
Во время первых попыток обучения Tacotron 2 мы разбирались с архитектурой нейронной сети: как с ней работать, как её обучать и использовать. Первые результаты нас не устроили, но потом удалось добиться устойчивого синтеза с минимальными проблемами. За исключением того, что спектрограмма переводилась в аудиоданные с помощью алгоритма Гриффин-Лима, который даёт крайне сильный «металлический отблеск» в полученной синтезированной речи.
Для наглядности я прикреплю к каждому из этапов примеры синтеза и оригинальной записи диктора.
Второй этап
Звучание синтеза было явно на уровне крайне сырого прототипа и вряд ли бы устроило какого-либо клиента. На начальном этапе мы сомневались в привлекательности будущего результата, поэтому решили пойти дальше и разбираться с более качественными подходами для перевода спектрограммы в аудиоданные. Теперь синтез речи стал полностью нейросетевым и звучит намного приятнее, естественнее. Так же были вручную проверены и очищены данные для обучения, что немного упростило и ускорило процесс обучения.
Третий этап
Добавили небольшие изменения в архитектуре нейронной сети, пересмотрели подходы к обучению моделей, подготовили аудиозаписи для обучения, добавили перевод слов в набор фонем. Благодаря этому получилось обучить модель всего на 3-х часах аудиозаписей, вместо 10-20 часов ранее.
Четвертый этап
Русский язык
На этом этапе мы провели более масштабную работу. Добавили ещё несколько изменений в архитектуре нейронной сети, оптимизировали процесс подготовки аудиозаписей и обучения, добавили расстановку ударений и обработку ударных и безударных фонем. Существенно доработали процесс обучения моделей, благодаря которым получилось обучить модель всего на 1-м часе аудиозаписей без особой потери в качестве и стабильности синтеза.
Английский язык
Параллельно мы записали 1 час с англоговорящим диктором и перенесли полученный результата с русского языка на английский. Архитектура нейронной сети и процессы обучения такие же, как на русском языке, но пока что без перевода слов в набор фонем и поддержки ударений. Модель для английского языка обучена так же на 1-ом часе аудиозаписей.
Нейросетевой синтез речи своими руками
Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
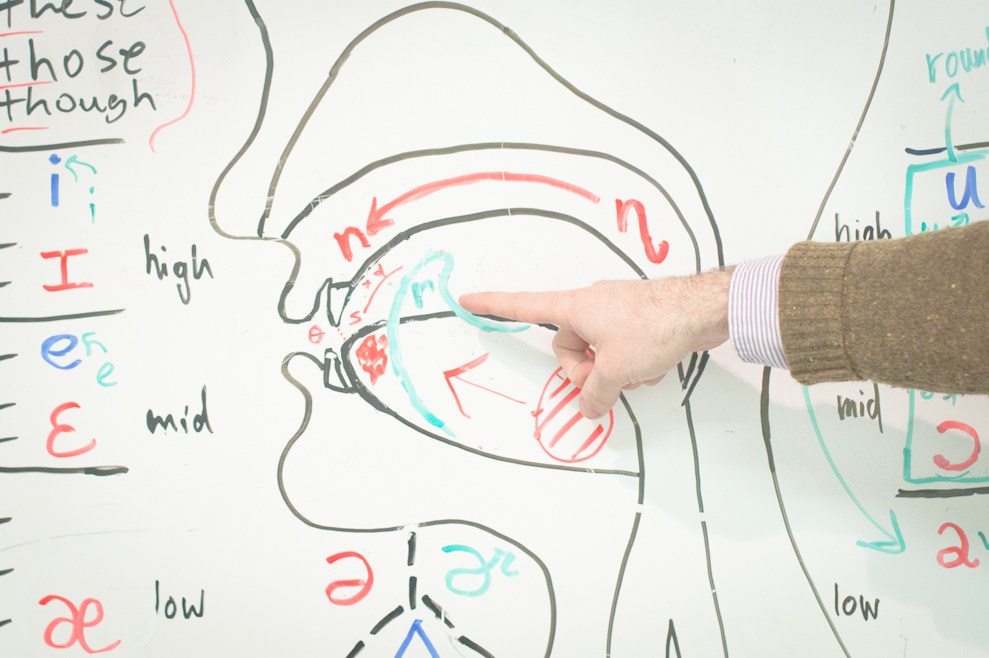
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Синтез речи
Чтобы построить систему синтеза речи, нужна целая команда специалистов из разных областей. По каждой из них существует целая масса алгоритмов и подходов. Написаны докторские диссертации и толстые книжки с описанием фундаментальных подходов. Давайте для начала поверхностно разберемся с каждой их них.
Лингвистика
Просодика
Фонетика
Акустика
- Подбор звуковых элементов. Системы синтеза оперируют так называемыми аллофонами — реализациями фонемы, зависящими от окружения. Записи из обучающих данных нарезаются на кусочки по фонемной разметке, которые образуют аллофонную базу. Каждый аллофон характеризуется набором параметров, таких как контекст (фонемы соседи), высота основного тона, длительность и прочие. Сам процесс синтеза представляет собой подбор правильной последовательности аллофонов, наиболее подходящих в текущих условиях.
- Модификация и звуковые эффекты. Для получившихся записей иногда нужна постобработка, какие-то специальные фильтры, делающие синтезируемую речь чуть ближе к человеческой или исправляющие какие-то дефекты.
Если вдруг вам показалось, что все это можно упростить, прикинуть в голове или быстро подобрать какие-то эвристики для отдельных модулей, то просто представьте, что вам нужно сделать синтез на хинди. Если вы не владеете языком, то вам даже не удастся оценить качество вашего синтеза, не привлекая кого-то, кто владел бы языком на нужном уровне. Мой родной язык русский, и я слышу, когда синтез ошибается в ударениях или говорит не с той интонацией. Но в тоже время, весь синтезированный английский для меня звучит примерно одинаково, не говоря уже о более экзотических языках.
Реализации
Мы попытаемся найти End-2-End (E2E) реализацию синтеза, которая бы взяла на себя все сложности, связанные с тонкостями языка. Другими словами, мы хотим построить систему, основанную на нейронных сетях, которая бы на вход принимала текст, а на выходе давала бы синтезированную речь. Можно ли обучить такую сеть, которая позволила бы заменить целую команду специалистов из узких областей на команду (возможно даже из одного человека), специализирующуюся на машинном обучении?
На запрос end2end tts Google выдает целую массу результатов. Во главе — реализация Tacotron от самого Google. Самым простым мне показалось идти от конкретных людей на Github, которые занимаются исследованиям в этой области и выкладывают свои реализации различных архитектур.
Я бы выделил троих:
- Kyubyong Park
- Keith Ito
- Ryuichi Yamamoto
Загляните к ним в репозитории, там целый кладезь информации. Архитектур и подходов к задаче E2E-синтеза довольно много. Среди основных:
- Tacotron (версии 1, 2).
- DeepVoice (версии 1, 2, 3).
- Char2Wav.
- DCTTS.
- WaveNet.
Нам нужно выбрать одну. Я выбрал Deep Convolutional Text-To-Speech (DCTTS) от Kyubyong Park в качестве основы для будущих экспериментов. Оригинальную статью можно посмотреть по ссылке. Давайте поподробнее рассмотрим реализацию.
Автор выложил результаты работы синтеза по трем различным базам и на разных стадиях обучения. На мой вкус, как не носителя языка, они звучат весьма прилично. Последняя из баз на английском языке (Kate Winslet’s Audiobook) содержит всего 5 часов речи, что для меня тоже является большим преимуществом, так как моя база содержит примерно сопоставимое количество данных.
Через некоторое время после того, как я обучил свою систему, в репозитории появилась информация о том, что автор успешно обучил модель для корейского языка. Это тоже довольно важно, так как языки могут сильно разниться и робастность по отношению к языку — это приятное дополнение. Можно ожидать, что в процессе обучения не потребуется особого подхода к каждому набору обучающих данных: языку, голосу или еще каким-то характеристикам.
Еще один важный момент для такого рода систем — это время обучения. Tacotron на том железе, которое у меня есть, по моим оценкам учился бы порядка 2 недель. Для прототипирования на начальном уровне мне показалось это слишком ресурсоемким. Педали, конечно, крутить не пришлось бы, но на создание какого-то базового прототипа потребовалось бы очень много календарного времени. DCTTS в финальном варианте учится за пару дней.
У каждого исследователя есть набор инструментов, которыми он пользуется в своей работе. Каждый подбирает их себе по вкусу. Я очень люблю PyTorch. К сожалению, на нем реализации DCTTS я не нашел, и пришлось использовать TensorFlow. Возможно в какой-то момент выложу свою реализацию на PyTorch.
Данные для обучения
Хорошая база для реализации синтеза — это основной залог успеха. К подготовке нового голоса подходят очень основательно. Профессиональный диктор произносит заранее подготовленные фразы в течение многих часов. Для каждого произнесения нужно выдержать все паузы, говорить без рывков и замедлений, воспроизвести правильный контур основного тона и все это в купе с правильной интонацией. Кроме всего прочего, не все голоса одинаково приятно звучат.
У меня на руках была база порядка 8 часов, записанная профессиональным диктором. Сейчас мы с коллегами обсуждаем возможность выложить этот голос в свободный доступ для некоммерческого использования. Если все получится, то дистрибутив с голосом помимо самих записей будет включать в себя точные текстовки для каждой из них.
Начнем
Мы хотим создать сеть, которая на вход принимала бы текст, а на выходе давала бы синтезированный звук. Обилие реализаций показывает, что это возможно, но есть конечно и ряд оговорок.
Основные параметры системы обычно называют гиперпараметрами и выносят в отдельный файл, который называется соответствующим образом: hparams.py или hyperparams.py, как в нашем случае. В гиперпараметры выносится все, что можно покрутить, не трогая основной код. Начиная от директорий для логов, заканчивая размерами скрытых слоев. После этого гиперпараметры в коде используются примерно вот так:
Далее по тексту все переменные имеющие префикс hp. берутся именно из файла гиперпараметров. Подразумевается, что эти параметры не меняются в процессе обучения, поэтому будьте осторожны перезапуская что-то с новыми параметрами.
Текст
Для обработки текста обычно используются так называемый embedding-слой, который ставится самым первым. Суть его простая — это просто табличка, которая каждому символу из алфавита ставит в соответствие некий вектор признаков. В процессе обучения мы подбираем оптимальные значения для этих векторов, а когда синтезируем по готовой модели, просто берем значения из этой самой таблички. Такой подход применяется в уже довольно широко известных Word2Vec, где строится векторное представление для слов.
Для примера возьмем простой алфавит:
В процессе обучения мы выяснили, что оптимальные значения каждого их символов вот такие:
Тогда для строчки aabbcc после прохождения embedding-слоя мы получим следующую матрицу:
Эта матрица дальше подается на другие слои, которые уже не оперируют понятием символ.
В этот момент мы видим первое ограничение, которое у нас появляется: набор символов, который мы можем отправлять на синтез, ограничен. Для каждого символа должно быть какое-то ненулевое количество примеров в обучающих данных, лучше с разным контекстом. Это значит, что нам нужно быть осторожными в выборе алфавита.
В своих экспериментах я остановился на варианте:
Это алфавит русского языка, дефис, пробел и обозначение конца строки. Тут есть несколько важных моментов и допущений:
- Я не добавлял в алфавит знаки препинания. С одной стороны, мы действительно их не произносим. С другой, по знакам препинания мы делим фразу на части (синтагмы), разделяя их паузами. Как система произнесет казнить нельзя помиловать?
- В алфавите нет цифр. Мы ожидаем, что они будут развернуты в числительные перед подачей на синтез, то есть нормализованы. Вообще все E2E-архитектуры, которые я видел, требуют именно нормализованный текст.
- В алфавите нет латинских символов. Английский система уметь произносить не будет. Можно попробовать транслитерацию и получить сильный русский акцент — пресловутый лет ми спик фром май харт.
- В алфавите есть буква ё. В данных, на который я обучал систему, она стояла там, где нужно, и я решил этот расклад не менять. Однако, в тот момент, когда я оценивал получившиеся результаты, выяснилось, что теперь перед подачей на синтез эту букву тоже нужно ставить правильно, иначе система произносит именно е, а не ё.
В будущих версиях можно уделить каждому из пунктов более пристальное внимание, а пока оставим в таком немного упрощенном виде.
Почти все системы оперируют не самим сигналом, а разного рода спектрами полученными на окнах с определенным шагом. Я не буду вдаваться в подробности, по этой теме довольно много разного рода литературы. Сосредоточимся на реализации и использованию. В реализации DCTTS используются два вида спектров: амплитудный спектр и мел-спектр.
Считаются они следующим образом (код из этого листинга и всех последующих взят из реализации DCTTS, но видоизменен для наглядности):
Для вычислений почти во всех проектах E2E-синтеза используется библиотека LibROSA (https://librosa.github.io/librosa/). Она содержит много полезного, рекомендую заглянуть в документацию и посмотреть, что в ней есть.
Теперь давайте посмотрим как амплитудный спектр (magnitude spectrum) выглядит на одном из файлов из базы, которую я использовал:
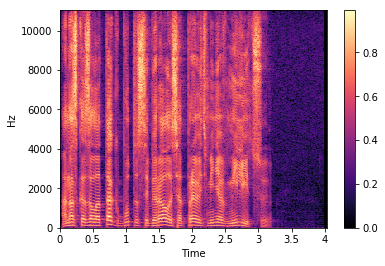
Такой вариант представления оконных спекторов называется спектрограммой. На оси абсцисс располагается время в секундах, на оси ординат — частота в герцах. Цветом выделяется амплитуда спектра. Чем точка ярче, тем значение амплитуды больше.
Мел-спектр — это амплитудный спектр, но взятый на мел-шкале с определенным шагом и окном. Количество шагов мы задаем заранее, в большинстве реализаций для синтеза используется значение 80 (задается параметром hp.n_mels). Переход к мел-спектру позволяет сильно сократить количество данных, но этом сохранить важные для речевого сигнала характеристики. Мел-спектрограмма для того же файла выглядит следующим образом:
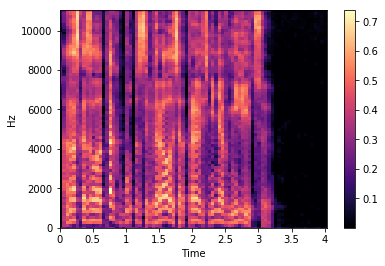
Обратите внимание на прореживание мел-спектров во времени на последней строке листинга. Мы берем только каждый 4 вектор (hp.r == 4), соответственно уменьшая тем самым частоту дискретизации. Синтез речи сводится к предсказанию мел-спектров по последовательности символов. Идея простая: чем меньше сети приходится предсказывать, тем лучше она будет справляться.
Хорошо, мы можем получить спектрограмму по звуку, но послушать мы ее не можем. Соответственно нам нужно уметь восстанавливать сигнал обратно. Для этих целей в системах часто используется алгоритм Гриффина-Лима и его более современные интерпретации (к примеру, RTISILA, ссылка). Алгоритм позволяет восстановить сигнал по его амплитудным спектрам. Реализация, которую использовал я:
А сигнал по амплитудной спектрограмме можно восстановить вот так (шаги, обратные получению спектра):
Давайте попробуем получить амплитудный спектр, восстановить его обратно, а затем послушать.
Синтез речи
Синтез речи (text-to-speech — tts) — это процесс генерирования речи по печатному тексту. SpeechKit позволяет озвучить любой текст на нескольких языках. При этом можно выбрать голос (мужской или женский) и интонацию. Настройка синтеза речи находится на отдельном табе «Синтез речи».
Включение синтеза происходит по клику на переключатель:

Общие настройки синтеза речи

В данном блоке выбирается голос озвучки текста, эмоциональная окраска и скорость воспроизведения записи.
- Выбор голоса. В данном поле вы можете выбрать один из нескольких голосов для воспроизведения. Для выбора доступны женские голоса: alyss, jane, oksana и omazh, и мужские: zahar и ermil.
- Эмоциональная окраска. Для выбора доступны следующие опции: радостный, раздраженный, нейтральный. Эти настройки применяются как фактической дорожке голосового сообщения в момент звонка, так и к блоку итогового текста для синтеза.
- Скорость воспроизведения записи. Здесь вы можете указать дробное значение-множитель для скорости воспроизведения записи. Тут можно указать значения от 0.1 до 3.0, а 1.0 выставлено по умолчанию.
Конструктор синтеза речи
Вы можете выбрать элементы, которые будут озвучиваться в голосовом оповещении оператору во время входящего звонка. Чтобы изменить порядок озвучивания фраз и параметров, перетащите плашки в нужной последовательности. Для передачи правильного ударения используйте «+» (плюс) перед ударной гласной. Например, гот+ов или def+ect. Чтобы отметить паузу между словами, используйте «-» (минус).
Обратите внимание. По умолчанию есть предустановленные блоки , которые нельзя удалить и передвинуть:
- Текст (для каждого виджета и варианта синтеза свой)
- Соединение по нажатию на клавишу (добавляется по умолчанию, если в настройках виджета установили «соединять с клиентом после нажатия клавиши оператором» )
Конструктор имеет три плашки: Рабочее время, Нерабочее время и Повторные попытки — для всех трех случаев можно настраивать свои собственные оповещения:

При клике на плашку раскрываются настройки и есть возможность добавить нужные блоки для озвучивания.
 Голосовой файл будет динамически меняться в зависимости от значений, которые приходят в параметрах времени заявки, отдела, канала, источника и кампании.
Голосовой файл будет динамически меняться в зависимости от значений, которые приходят в параметрах времени заявки, отдела, канала, источника и кампании.

Опция копирования набора блоков другого типа синтеза.

Данный блок дает возможность копировать из другого типа синтеза выбранные наборы, тексты, содержащиеся в блоках, а также порядок блоков.
Далее идет разбор каждого поля.
Давайте посмотрим пример корректного использования передаваемых данных. В данный момент передаются 5 пар Название поле — Значение поля:
| Название поля | Значение поля |
| Имя | Иван |
| Фамилия | Петров |
| Комментарий | Хочу купить машину |
| Тип заявки | Форма обратной связи |
| Раздел сайта | Каталог машин |
| Название поля | Значение поля |
| lead Product | BMW |
| lead Type | credit request |
| contact ID | 343434 |
| lead ID | 4545454 |
| lead Channel | web-site |
Для оператора эти данные будет сложно воспринять на слух. Поэтому мы рекомендуем использовать эти данные так:
| Название поля | Значение поля | Комментарий |
| Продукт | BMW | |
| Тип заявки | credit request | |
| contact ID | 343434 | Не ставить галочку для синтеза у дополнительного поля 3, т.к. это информация для служебного пользования |
| lead ID | 4545454 | Не ставить галочку для синтеза у дополнительного поля 4, т.к. это информация для служебного пользования |
| Канал заявки | web-site |
10) Для соединения нажмите *0*
Фраза, которой заканчивается оповещение оператору. Доступна при включенной опции «Соединять с клиентом после нажатия клавиши оператором». Данная фраза не может быть отключена от воспроизведения. Единственный параметр, который настраивается здесь — цифра, которая проговаривается оператору.
Выбор цифры происходит в пункте «Соединять с клиентом после нажатия клавиши оператором».
Итоговый текст для синтеза

В данном блоке вы увидите фразу, которую услышит оператор, согласно выбранным полям и введенным ранее текстам. Однако, его можно использовать несколькими способами:
1) Ознакомление с итоговым вариантом текста. Эту фразу можно прослушать, а текст прочитать или скопировать и передать менеджерам для ознакомления с функционалом обратного звонка.
2) Использование поля для тестирования синтеза речи. Текст внутри данного поля можно изменять, вводить туда свои значения и воспроизводить получившийся текст. Это особенно важно для определения как именно будет звучать ваши каналы, источники и кампании из ваших рекламных систем. Просто введите значение вашей кампании в данное поле и послушайте насколько корректно и понятно она звучит. Важно, что введенный здесь текст никак не повлияет на заданные ранее настройки. При перезагрузке страницы вы снова увидите тот текст, который будет воспроизведен оператору на основе выбранных полей и введенных текстов.
3) Определение некорректных ударений. Вы можете прослушать получившийся текст, найти слова, где синтез некорректно устанавливает ударения и вручную проставить ударения в конструкторе. Для передачи правильного ударения используйте «+» (плюс) перед ударной гласной. Например, гот+ов или def+ect. Чтобы отметить паузу между словами, используйте «-» (минус).
Как установить голосовые данные для синтеза речи?
Если Вы используете Синтезатор речи Google, нажмите кнопку «i» рядом названием. В меню «Настройки» нажмите «Установка голосовых данных». Нажмите на выбранный Вами язык. Вы увидите различные голоса, перечисленные и пронумерованные, начиная с «Голоса I».
Как установить синтезатор речи?
Чтобы настроить эту функцию, выполните следующие действия:
- Откройте приложение «Настройки» .
- Нажмите Спец. …
- Выберите синтезатор речи, используемый язык, скорость речи и тон голоса. …
- Чтобы послушать короткий отрывок синтезированной речи, нажмите Воспроизвести.
- Если вы хотите использовать другой язык, нажмите «Настройки»
Как отключить голосовой синтезатор речи Google?
Второй способ: необходимо войти в меню настроек смартфона и выбрать пункт «Приложения». В открывшемся меню находим «Синтезатор речи » и нажимаем «Остановить принудительно».
Как настроить синтезатор речи Google?
Синтезатор речи Google на смартфоне — что это и как работает?
- Далее нужно выбрать пункт «Синтез речи». …
- После изменения параметров вернитесь в раздел «Специальные возможности» и включите «Озвучивание при нажатии».
- Если соответствующего пункта нет, установите утилиту Android Accessibility Suite из каталога Google Play.
Можно ли отключить синтезатор речи?
Заходим в Настройки > Приложения > Сторонние. Перед нами появится большой список программ. Выбираем, к примеру, Синтезатор речи Google. Выбираем пункт Отключить.
Для чего нужен синтезатор речи на Андроиде?
Напомним, Синтезатор речи Google озвучивает текст, который виден на экране устройства. Это можно использовать для прочтения книг вслух, в переводчиках для озвучивания произношения слов, а также при использовании TalkBack и других специальных возможностей озвучиваются действия пользователя.
Для чего нужен синтез речи?
Синтез речи или Text-to-Speech (TTS) — технология преобразования текста в речь. … Параметрический — построение вероятностной модели, которая подбирает акустические свойства звукового сигнала для данного текста. С помощью этого подхода можно создавать речь, практически не отличимую от человеческой.
Как работает синтезатор речи у Хокинга?
Стивен Хокинг вводит текст в синтезатор речи при помощи мимической мышце на своей щеке. Это единственная мышца в теле профессора, которой он по-прежнему может двигать, поэтому специальный датчик закреплён именно напротив неё.
Как отключить голосовое сопровождение на телефоне Samsung?
Как отключить голосовой помощник S Voice на Samsung Galaxy:
- Двойной тап на кнопке «Домой», чтобы открыть S Voice.
- Нажмите на кнопку «Меню» в верхнем правом углу приложения
- Нажмите «Настройка»
- Снимите галочку на «Открыть с помощью кнопки Домой».
Как отключить говорящий телефон?
Двумя пальцами прокрутите вниз меню, найдите и коснитесь Специальные возможности, затем дважды коснитесь Специальные возможности. Коснитесь TalkBack, затем дважды коснитесь TalkBack. Коснитесь переключателя рядом с Вкл. или TalkBack, затем дважды коснитесь переключателя.
Как сделать так чтобы гугл читал текст?
Как включить или отключить программу чтения с экрана
- На телефоне или планшете Android откройте приложение «Настройки» …
- В верхней части экрана нажмите Данные и персонализация.
- В разделе «Общие настройки веб-интерфейса» выберите Специальные возможности.
- Включите или выключите параметр Программа чтения с экрана.
Что такое синтез речи на телефоне?
Функция синтеза речи позволяет озвучивать информацию, отображаемую на экране Вашего устройства. Вместе со службой TalkBack эта функция помогает слабовидящим пользователям взаимодействовать с их устройствами.
Что будет если я удалю сервисы Google Play?
Хотя вы можете удалить его, он будет автоматически переустановлен на вашем устройстве, поскольку он является расширением экосистемы Google Play, и Google автоматически обновляет сервисы Google Play на всех поддерживаемых устройствах через Google Play Store, чтобы обеспечить согласованность API на всех устройствах и …
Можно ли удалять данные сервиса Google Play?
Как очистить данные, хранящиеся в службах Google Play
Откройте «Настройки» и перейдите в настройки диспетчера приложений в разделе «Дополнительно». Тут вы найдете пункт «сервисы Google Play». Он то нам и нужен. Далее вам нужно лишь нажать кнопку «Очистить кэш» и на этом «базовое» очищение будет закончено.
# Синтез речи
Познакомимся, как использовать Python для преобразования текста в речь с использованием кроссплатформенной библиотеки pyttsx3 . Этот пакет работает в Windows, Mac и Linux. Он использует родные драйверы речи, когда они доступны, и работает в оффлайн режиме.
Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Есть функции, которые здесь не рассматриваются, такие как система событий. Вы можете подключить движок к определенным событиям:
- можно посчитать, сколько слов сказано, и обрезать его,
- можно проверить каждое слово и отрезать его, если есть неуместные слова.
Всегда обращайтесь к официальной документации для получения наиболее точной, полной и актуальной информации https://pyttsx3.readthedocs.io/en/latest/
# Установка пакетов в Windows
Используйте pip для установки пакета. В Windows, вам понадобится дополнительный пакет pypiwin32 , который понадобится для доступа к собственному речевому API Windows.
# Преобразование текста в речь
Для первой программой озвучивания текста используем код:
В примере программы даны две фразы на английском и на русском языке. Существует голосовой набор по умолчанию, поэтому вам не нужно выбирать голос. В зависимости от версии windows будет озвучена соответствующая фраза. Например для английской версии windows услышим: «I can speak!»
# Доступные синтезаторы по умолчанию
Доступные голоса будут зависеть от версии установленной систем. Вы можете получить список доступных голосов на вашем компьютере. Обратите внимание, что голоса, имеющиеся у вас на компьютере, могут отличаться от чьей-либо машины.
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Получить список доступных голосов можно так:
Результат будет примерно таким:
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID.
# Установка дополнительных голосов в Windows
При желании можно установить дополнительные языковые пакеты согласно инструкции https://support.microsoft.com/en-us/help/14236/language-packs#lptabs=win10
Для этого выполните указанные ниже действия.
Нажмите кнопку Пуск , затем выберите Параметры > Время и язык > Язык.
В разделе Предпочитаемые языки выберите Добавить язык.

В разделе Выберите язык для установки выберите или введите название языка, который требуется загрузить и установить, а затем нажмите Далее.
В разделе Установка языковых компонентов выберите компоненты, которые вы хотите использовать на языке.

ВНИМАНИЕ: отключите первый пакет: «Install language pack and set as my Windows display language» — «Установите языковой пакет и установите мой язык отображения Windows»

Иначе переустановиться язык отображения операционной системы.
Нажмите Установить.
После установки нового языкового пакета перезагрузка не требуется. Запустив код проверки установленных языков. Новый язык должен отобразиться в списке.
Не все языковые пакеты поддерживают синтез речи. Для этого опция Speech должны быть в описании установки.
# Выбор голоса
Установить голос можно методом setProperty() . Например, используя голосовые идентификаторы, найденные ранее, вы можете настроить голос. В примере показано, как настроить один голос, чтобы сказать что-то, а затем использовать другой голос из другого языка, чтобы сказать что-то другое.
В Windows идентификатором служит адрес записи в системном реестре:
# Как озвучить системное время в Windows
Пример консольного приложения которое будет называть неточное время может быть реализованно следующим кодом:
Привер риложения которое каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+C в Windows.
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь ресурсы производительности, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры.
# Упражнения tkinter
- Напишите программу часы, которая показывает текущее время и имеет кнорку, при нажатии на которую можно ушлышать текуще время.
- Внесите измеения с программу что бы при произненсении времени программа корректно склоняла слова: «часы» и «минуты».
- Добавьте с помощью радиокнопки выбор языка озвучки часов.
# Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
# Упражнения tkinter
- Напишите программу текстовым полем и кнопкой которая будет озвучивать написанное.
- Добавьте меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
# Модуль Google TTS — голоса из интернета
Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Для работы необходимо установить пакет:
Простейший код, который сохраняет текст на русском в аудиофайл:
После запуска этого кода в директории, где лежит скрипт, появится запись. Для воспроизведения в питоне придется использовать pygame или pyglet.